
Event Sourcing is een alternatieve manier om je gegevens op te slaan. Met Event Sourcing wordt elke toestandsverandering opgeslagen als een afzonderlijk record (een event), in tegenstelling tot toestands-gebaseerde opslag die alleen de laatste versie van een toestand van een entiteit bijhoudt.
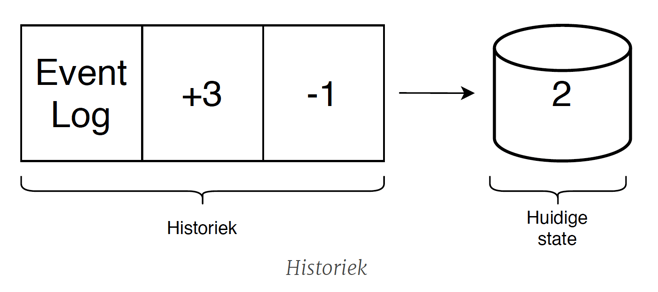
Bij de traditionele manier om de state van een applicatie op te slaan, capteren we de huidige state en slaan we deze op in een relationele/NoSQL database. Een nadeel hierbij is dat we geen mogelijkheid hebben om te kunnen afleiden hoe we tot de huidige state gekomen zijn. Het is mogelijk om de geschiedenis bij te houden in een apart auditing model, maar dit heeft een zekere complexiteit. In Event Sourcing daarentegen houden we alle "events" bij die betrekking hebben op de toestand van de applicatie. Elk event is een bedrijfsfeit en beschrijft een toestandsverandering die in het systeem heeft plaatsgevonden. De huidige state kan dan worden gereconstrueerd op basis van de volledige geschiedenis van events.
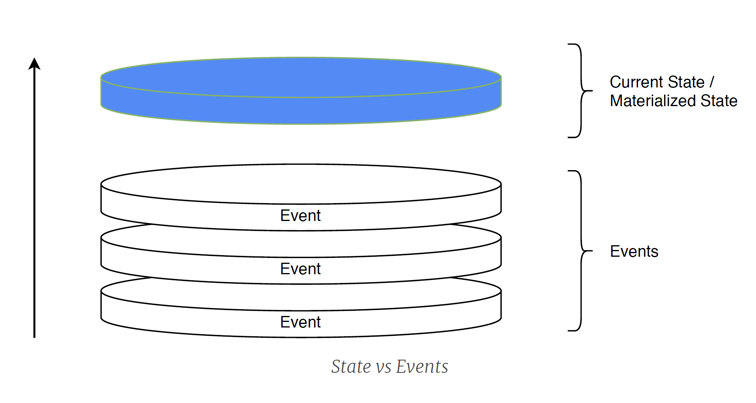
Bij Event Sourcing, wanneer we een volledige stroom events beschikbaar hebben, is het altijd mogelijk om de huidige toestand van een entiteit af te leiden door alle events voor die entiteit te verwerken. Het omgekeerde is niet mogelijk, zodat we interessante historische informatie verliezen wanneer we alleen de huidige toestand opslaan.
Laten we als voorbeeld een winkelwagendienst nemen: met een Event Sourcing-aanpak zouden we elke wijziging die de gebruiker aanbrengt, opslaan in een reeks events. De huidige toestand van het winkelwagentje kan dan worden afgeleid door een samenstelling van alle gebeurtenissen.
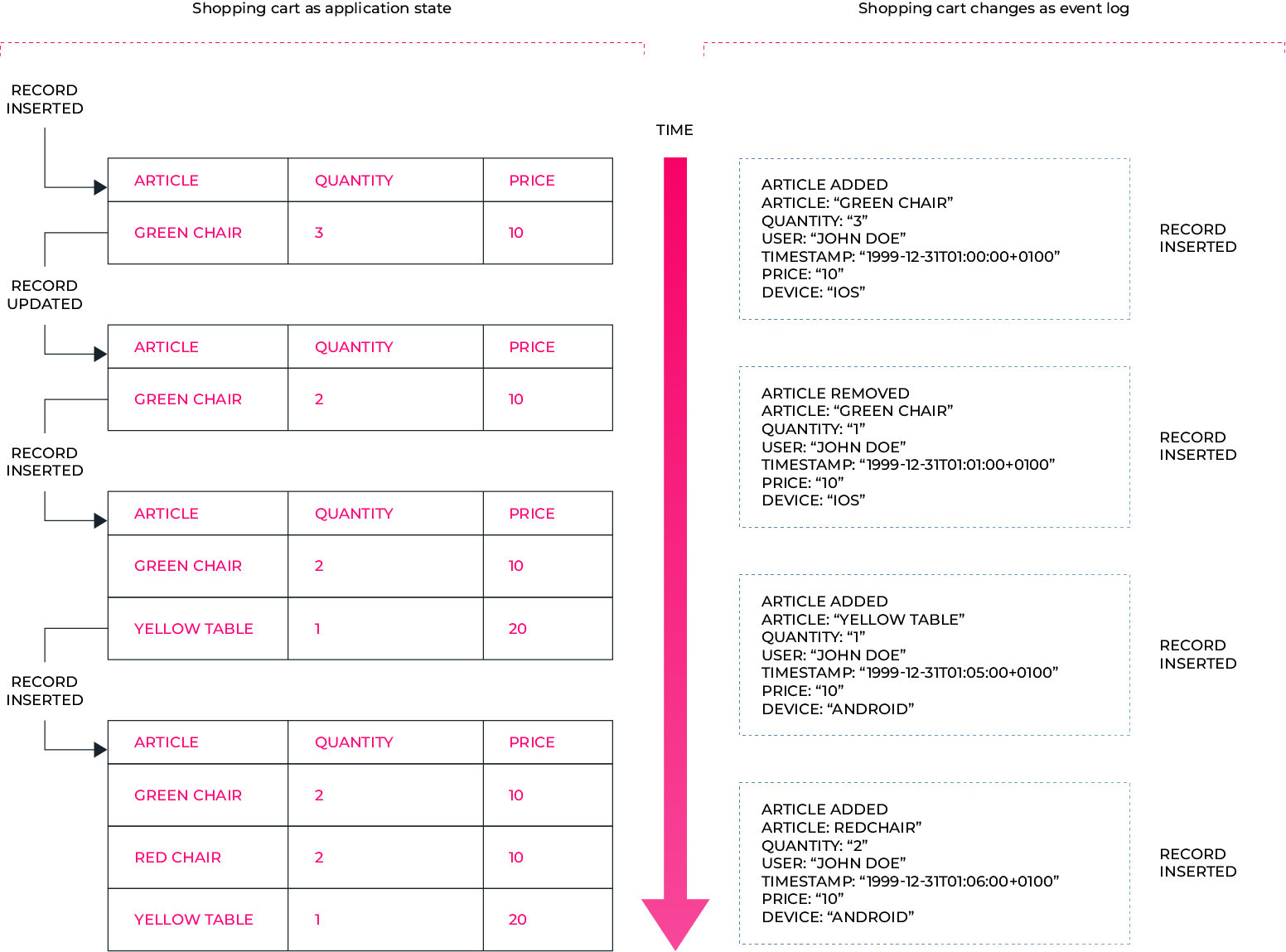
Natuurlijk kan een Event Sourcing aanpak worden gemengd met een meer traditionele aanpak om een state op te slaan. Bovendien is het mogelijk Event Sourcing te gebruiken voor slechts een deel van de entiteiten, wat voordelig is.
Voordelen
Audit trail
De geschiedenis van hoe een entiteit tot haar huidige toestand is gekomen, zit inherent vervat in de opgeslagen events. De events vormen een consistente auditgeschiedenis, omdat het in feite om dezelfde gegevens gaat. Er hoeft niet altijd een formele noodzaak voor auditing te zijn (denk aan financiële toepassingen). Een audit trail is ook een zeer nuttige logging component die kan worden geraadpleegd in geval van productie problemen.
Historische queries
Met een typische relationele database kan de data zoals die nu bestaat ondervraagd worden. Het is echter niet altijd evident om de historische context en evolutie van de data te ondervragen.
Neem het voorbeeld van het winkelwagentje hierboven: op een bepaald moment wil een zakelijke belanghebbende wellicht weten hoe vaak gebruikers een product toevoegen, verwijderen en vervolgens opnieuw toevoegen aan hun winkelwagentje. Als de database dan alleen de huidige status vastlegt, zijn de gegevens om deze bedrijfsvraag te beantwoorden niet beschikbaar.
Met Event Sourcing is het mogelijk de event flow te analyseren en op basis daarvan bedrijfsinformatie af te leiden. Dit blijkt vaak informatie te zijn waar tijdens het initiële ontwerp van het systeem geen rekening mee is gehouden.
Het is ook mogelijk om nieuwe inzichten toe te voegen, gebaseerd op de activiteit in het systeem, zonder de rest van de code te hoeven veranderen die events uitschrijft. Het wordt mogelijk om nieuwe bedrijfsvragen te beantwoorden door naar de geschiedenis van de toepassing te kijken. En dat is natuurlijk erg nuttig.
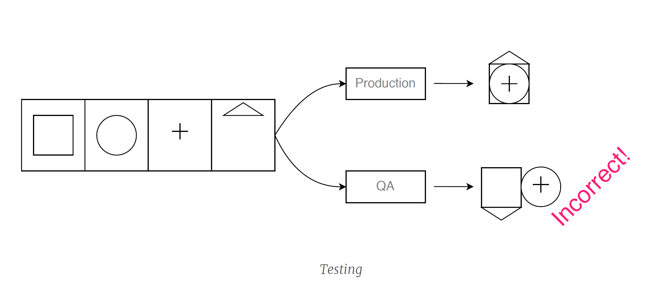
Testing - debugging
Event-systemen zijn gemakkelijk te testen en te debuggen. Enerzijds kunnen events tijdens het testen worden gesimuleerd, en anderzijds biedt event logging nuttige input voor debugging.
Wanneer zich bijvoorbeeld een probleem voordoet op de productieomgeving, kan het eventlogboek onder gecontroleerde omstandigheden opnieuw worden afgespeeld. Dit genereert inzicht in hoe het systeem in een slechte toestand terecht is gekomen. We beginnen bij het "begin van de tijd" en spelen events één voor één af. Op deze manier ontdekken we welke gebeurtenis verantwoordelijk is voor het abnormale gedrag. Dit is zeer nuttig voor het debuggen van een applicatie. We kunnen ook teruggaan naar een willekeurig punt in de tijd om de toestand van de applicatie op dat moment te controleren. Met Event Sourcing is het mogelijk om naar gerichte toestandstesten van de applicatie te kijken bovenop end-to-end testen. We doen dit door een reeks gebeurtenissen opnieuw af te spelen, en controleren of de uiteindelijke toestand van de applicatie overeenkomt met de verwachting.
CRUD: model vs database.
Bij de implementatie van een traditioneel CRUD-model hebben wij gewoonlijk een Java-object in het geheugen en een bijbehorende (aanpasbare) rij in een relationele database. Daarbij kunnen we tegen een 'object-relationele impedantie mismatch' aanlopen. In de meeste gevallen gebruiken wij "Object Relational mapping" frameworks om de verschillen tussen de Java objecten en de database rijen te beheren. Dit voegt enige complexiteit toe aan het systeem.
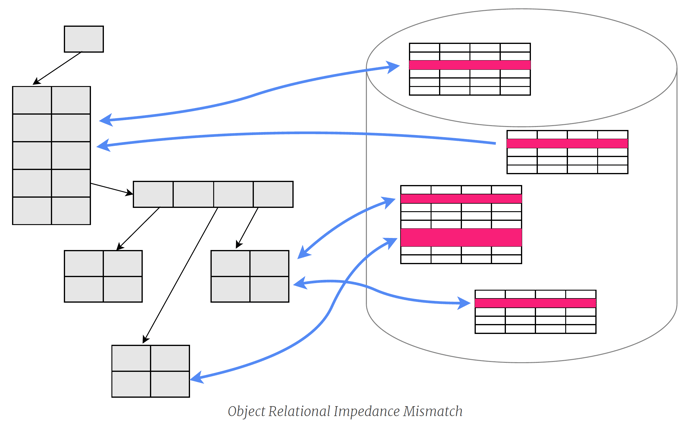
In een Event Sourcing architectuur wordt de database in wezen een append-only stroom van gebeurtenissen. Noch de toestand van een entiteit, noch de relaties tussen entiteiten worden rechtstreeks in het databaseschema opgeslagen. Hierdoor wordt de code voor het schrijven en lezen naar de database aanzienlijk eenvoudiger.
Omgaan met fouten
Hoe graag we soms ook denken dat onze code foutloos is, blijkt in werkelijkheid dat een aanzienlijk deel van de ontwikkeltijd wordt besteed aan het debuggen of updaten van bedrijfsprocessen die niet helemaal correct zijn geïmplementeerd. Een architectuur die erkent dat fouten maken onderdeel is van software ontwikkeling kan alleen maar bijdragen aan de iteratiesnelheid van een project.
Een traditioneel current-state model voor persistentie is niet altijd evident. Wanneer er een fout in de code zit die de current state op de verkeerde manier aanpast, moeten we compenserende transacties uitvoeren om de gegevens te corrigeren. We richten ons op het zo snel mogelijk aanwijzen van de fout, zodat er zo min mogelijk wijzigingen, gebaseerd op onjuiste gegevens, worden doorgevoerd.
Een Event Sourcing systeem is in die zin meer vergevingsgezind ten aanzien van fouten, omdat we ons kunnen richten op het herstellen van de fout, en we de toestand opnieuw kunnen opbouwen op basis van het bijgewerkte systeem.
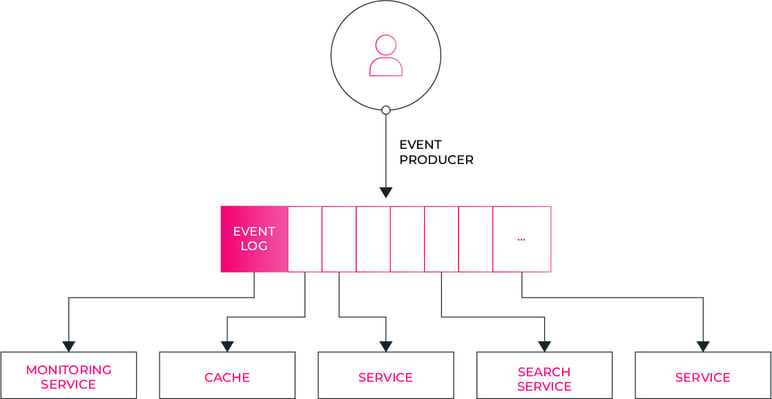
Nieuwe gebruikers van de data: in een Event Sourced systeem kan een event log fungeren als de centrale hub waar de data wordt geproduceerd en geconsumeerd. Een pub/sub-architectuur minimaliseert de noodzaak om allerlei API's en eindpunten aan te bieden voor elke nieuwe gebruiker van de gegevens.
Agiliteit
Samenvattend valt er veel te zeggen voor een Event Sourced architectuur. Een current state architectuur is geoptimaliseerd voor consistentie, maar niet noodzakelijk voor aanpassingen. Aangezien we bij grote applicaties vaak zien dat de snelheid van aanpassingen afneemt, kan het interessant zijn om na te denken over alternatieven.
Met een Event Sourced architectuur is het eenvoudig om op elk moment te experimenteren met nieuwe functionaliteiten. Het is niet nodig om hiervoor databaseschema's aan te passen of data te migreren. Experimenteren met nieuwe functionaliteiten kan door de nieuwe code te deployen, eventueel met een andere database waar de nieuwe data tijdens het experiment wordt verzameld. Om wendbaarheid te behouden tijdens de ontwikkeling van een systeem kan het interessant zijn om de architectuur zo in te richten dat het introduceren van nieuwe functionaliteiten en het testen van experimenten eenvoudiger wordt.
Simpliciteit
Softwareontwikkeling is nooit eenvoudig. Enige vereenvoudiging is interessant als het helpt om correct te analyseren en te voorspellen hoe een systeem zich zal gedragen. Een Event Sourced-architectuur is in sommige opzichten een eenvoudiger abstractie dan een monolithische statefull-benadering. Wanneer gegevens worden omgezet in een event log, wordt het gemakkelijker om te redeneren over de verschillende gegevensstromen.
Nadelen
Event Sourcing is niet altijd gemakkelijk te implementeren en is een minder bekende architectuurstijl, wat zorgt voor een (steile) leercurve.
Het is niet eenvoudig om queries uit te voeren op een Event Store, omdat de meeste queries eerst de toestand van de bedrijfsentiteiten zouden moeten reconstrueren. Dat is een nadeel, en daarom wordt vaak gebruik gemaakt van CQRS (Command Query Responsibility Segregation pattern) om query's uit te voeren. Hieruit volgt dat de applicatie op haar beurt in staat moet zijn om te gaan met uiteindelijke consistentie.
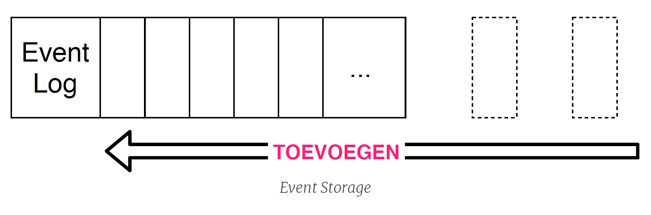
Event Storage
Bij het bouwen van een Event Sourced systeem zijn er verschillende opties met betrekking tot persistentie. Bijvoorbeeld door gebruik te maken van event sourcing systemen zoals EventStore of Axon Server, NoSQL databases of traditionele relationele databases. Het is ook mogelijk om event sourcing te ontwikkelen bovenop een message broker zoals Apache Kafka.
In tegenstelling tot het traditionele Create, Read, Update & Delete (CRUD) model voor datapersistentie, wordt persistentie in het Event Sourced model bereikt door alle toestandsveranderingen op te slaan als events. De historische gebeurtenissen zijn de zakelijke feiten.
Gewoonlijk slaan wij alle wijzigingsrecords zo op dat zij een verzameling van onveranderlijke records vormen. Immers, een gebeurtenis is een feit dat is gebeurd, en feiten kunnen niet worden gewijzigd.
Resources
1. Martin Kleppmann’s Designing Data-Intensive Applications of 1 van ‘s mans talks zoals ’Using logs to build a solid data infrastructure’ 2. Martin Fowler: Event Sourcing

