


Historiek van Business Process Management
Wanneer je ettelijke jaren carrière op jouw palmares hebt staan, heb je wellicht een flashback naar de jaren '90 wanneer je "Business Process Management" hoort. BPM was toen een hot topic, met proces-optimalisaties of zelfs business process re-engineering. Je weet wel, het from scratch hertekenen van je business processen als brainstorm om optimale operationele efficiëntie te bereiken.
Deze periode ging hand in hand met de ontwikkeling van heel wat BPM en workflow tools. Velen daarvan lieten een kwalijke reputatie achter. Ze bleken complex, duur, onpraktisch en verantwoordelijk voor een stevige vendor lock-in te zijn. Software-ontwikkelaars ervaarden de BPM Platformen van toen als te zwaar, log, en gecompliceerd.
Op dat moment waren er geen eenduidige standaarden bepaald voor proces-modellering en proces-automatisatie (de BPMN 1.0 standaard dateert pas van 2007), wat de aanvaarding en integratie van deze tools bemoeilijkte.
Ondertussen - een meevaller - zijn we ongeveer 25 jaar verder en evolueerden BPM engines tot lichte libraries die zich naadloos inpassen in moderne software en cloud-omgevingen. Ze gaan hand in hand met nieuwe onderwerpen als Artificial Intelligence (o.a. Machine Learning) en RPA (Robotic Process Automation).
In deze whitepaper kom je te weten waarom wij je aanraden om BPM een (tweede) kans te geven. Dit doen we vanuit een eigentijds beeld rond huidige mogelijkheden én oplossingen die BPM ondertussen biedt. Daarnaast trachten we je een klare kijk te geven op waarom een alignering tussen business en IT gevrijwaard dient te worden, en geven we je heel wat best practices mee over hoe dat in zijn werk gaat.

Wat is een BPM Engine?
Een BPM Engine bestaat om uitgetekende business processen als configuratie in software te integreren. In plaats van een omslachtige vertaalslag van business specificaties naar computer-code, worden de modellen direct in het systeem ingeladen. Dat leidt tot tijdswinst, minder fouten en een hoge transparantie van hoe de software werkt.
De werkstroom tussen allerlei business activiteiten worden rechtstreeks vanop de tekentafel in de software geïnjecteerd. Ook kan de status van lopende processen worden gerapporteerd vanuit dit beeld. Menselijke input wordt op de nodige momenten gevraagd, communicatie met externe systemen wordt automatisch afgehandeld, en bovenop dit alles krijg je een aantal dashboards en rapporteringen die duidelijk inzicht geven hoe jouw deels geautomatiseerde business loopt. Hierop gebaseerd kan je op zoek gaan naar verdere optimalisatie-mogelijkheden.
Een belofte van BPM Engines is meestal dat werkstromen of proces-definities aangepast kunnen worden door niet-technici (procesbeheerders of domein-experts). In de praktijk is dit vaak niet realistisch of zelfs niet wenselijk in functie van wijzigingsbeheer. Dit neemt echter niet weg dat software baseren op procesmodellen tot een hoge mate van inzichtelijkheid én grote herkenbaarheid leidt bij business mensen. Alsook dat de logging en realtime-informatie over procesverloop interessant kan zijn voor zeer uiteenlopende doeleinden.
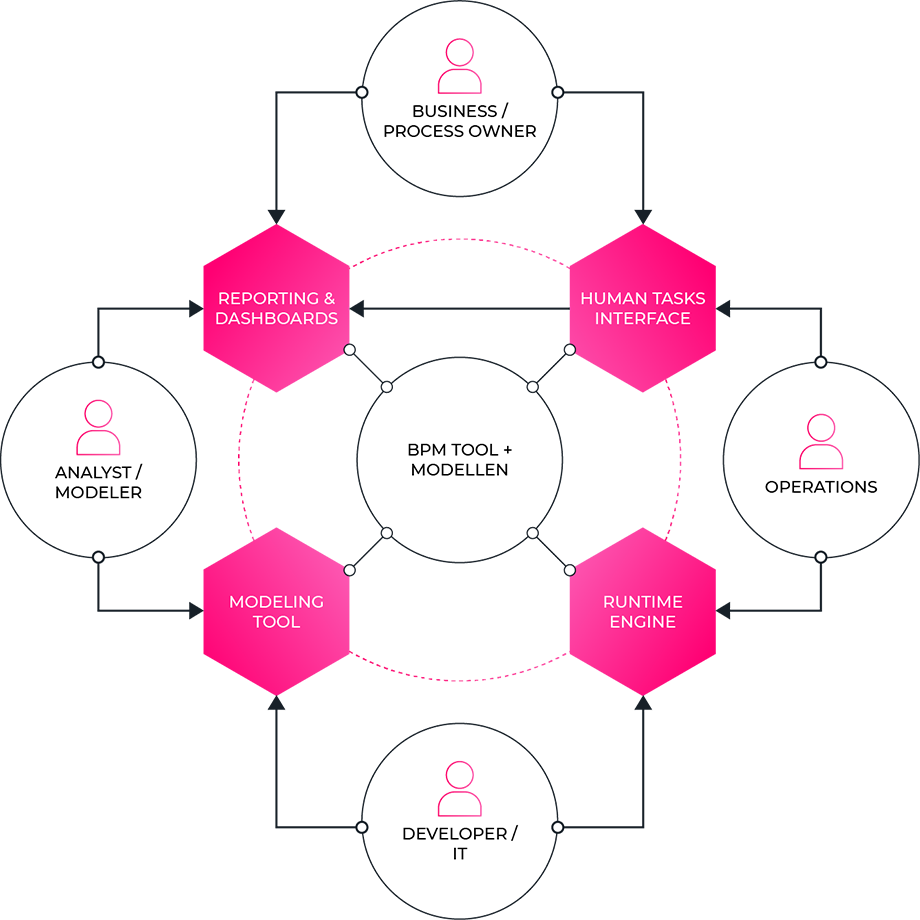
Een typische BPM platform bestaat uit:
- Een modelleringstool voor het uittekenen van:
- Process modellen - werkstromen waar de volgorde van acties en beslissingen duidelijk is.
Meestal wordt hier de BPMN standaard (Business Process Model and Notation) gehanteerd. - Case modellen - werkstromen waar niet altijd een sequentieel proces in te vinden is, maar toch een aantal duidelijke business rules vertonen.
Typisch werkt men hier volgens de CMMN standaard (Case Management Model and Notation) - Beslissingsmodellen - Om business-beslissingen expliciet te modelleren en in werking te zetten zonder omzetting naar software-code door een programmeur.
Hiervoor is de DMN standaard (Decision Management and Notation) gangbaar.
- Process modellen - werkstromen waar de volgorde van acties en beslissingen duidelijk is.
- Een Runtime Engine die de procesmodellen in uitvoering brengt.
- Een Taak-applicatie die toelaat om alle manueel uit te voeren taken (beslissingen, goedkeuringen, enz...) af te werken, vaak vergezeld van mogelijkheden om timeouts in te stellen, taken te delegeren, binnen teams te verdelen, enzovoort.
- Dashboards en Rapportering die alle activiteiten en performantie daarvan rapporteren en eventuele foutsituaties onder de aandacht brengen.
Teveel organisaties probeerden in-house ontwikkeling van workflow-oplossingen. Dat is door huidige standaardisatie en het aanbod van stabiele, bewezen BPM tools niet zo zinvol meer. Twee voorbeelden van BPM Engines uit de Java-wereld die zowel een open source als commerciële versie aanbieden zijn Flowable en Camunda.
Business Process Management - voor beginners
Je bent voldoende vertrouwd met deze materie? Ga dan naar het volgende hoofdstuk.
Laten we starten met een korte opfrissing van Business Processen en BPM kennis.
Wat is een business process nu ook alweer?
Een business process beschrijft een reeks activiteiten en beslissingen die samen leiden naar een businessdoel dat waarde oplevert.
Elk proces bevat in grote lijnen:
- Eén of meerdere gebeurtenissen (events) die de start van een proces betekenen.
Een situatie die zich voordoet, invoer van een gebruiker, een bericht dat binnenkomt, een moment in de tijd, e.d. - Eén of meerdere eind-situaties (outcomes) die het einde van een proces betekenen.
Bijvoorbeeld: een dossier werd aanvaard, of afgewezen, factuur werd betaald, enz... - dit kan zowel positieve als negatieve afloop betekenen. - Een logische sequentie in activiteiten met daartussen beslissingspunten of gateways om dingen voorwaardelijk te maken of eventueel te herhalen. An sich maakt het niet uit of een activiteiten manueel, digitaal of volledig geautomatiseerd uitgevoerd worden. De logica rond de activiteiten wordt ook als 'de workflow' benoemd.
- Een aantal actoren die bij het proces betrokken zijn - typisch worden hier organisaties (klant, afdelingen van de eigen organisatie, ...) en daarbinnen rollen benoemd (een verkoper, manager, enz...).
Aan de hand van een eenvoudig voorbeeld BPMN Proces Model overlopen we de belangrijkste elementen:
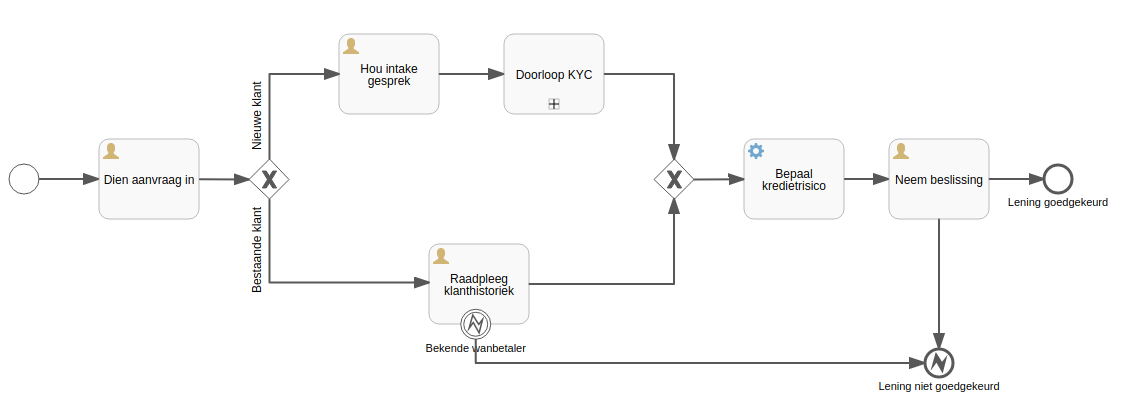
- Eén of meerdere start events, die aangeven wanneer en waarom een proces begint te lopen. Dit kan een menselijke beslissing zijn, maar ook op tijd of op basis van nieuwe informatie die binnenkomt, gebaseerd zijn (een factuur, een bericht, ...).
- Eén of meerdere end events, die aangeven in welke eindsituatie een proces kan aflopen. Deze kunnen zowel verwacht en wenselijk als onverwacht of onwenselijk zijn.
- Tussen start en einde is een sequentie van activities te vinden. Dit zijn processtappen die genomen moeten worden om naar een einde toe te werken. De activities worden met elkaar verbonden door de process flow.
- Binnen de process flow kan je gateways gebruiken om de control flow weer te geven. Dit betreft het uitdrukken welke activiteiten of hele paden voorwaardelijk zijn, of net in parallel worden uitgevoerd.
- Optioneel (niet gebruikt in het voorbeeld) kunnen pools gebruikt worden voor het weergeven van organisaties ("de klant", "onze organisatie", "de overheid") of afdelingen ("boekhouding", "sales"), die met elkaar enkel asynchroon (via messages) communiceren. Zo'n pool kan in wezen nog opgedeeld worden in één of enkele verschillende swimlanes, die verschillende rollen of actoren weergeven (een "manager", een "verkoper", de "customer service afdeling", enz...).
Een pool kan als een blackbox gemodelleerd worden zodat je enkel aandacht hebt voor de berichten die in en uit gaan, en dus niet kijkt naar de manier waarop deze intern in die organisatie of afdeling worden afgehandeld. Deze kan je perfect in een ander procesmodel uitwerken. Wanneer het over externe organisaties gaat, heb je vaak geen zicht op hoe het proces daar net in z'n werk gaat. Elk procesmodel heeft minstens één whitebox pool, waarin het gedetailleerde procesverloop wél uitgewerkt wordt.
Het ene process is het andere niet
Processen kunnen opgedeeld worden in kortlopende en langlopende processen.
- Bij kortlopende processen, ook beschreven als Straight-Through-Processing (STP), is het typisch dat alle activiteiten met een hoge mate van automatisatie doorlopen worden. Er komt geen menselijke interactie bij kijken. Denk aan het proces van een geautomatiseerde kredietscoring of de generatie en verzending van een digitaal document.
- Langlopende processen bevatten activiteiten die tijd in beslag nemen, en eventueel nieuwe informatie of tussenkomst van andere partijen vereisen.
Deze kunnen dagen, weken of zelfs jaren in beslag nemen (denk aan het proces voor terugbetaling van een lange-termijn lening, enz...)
Veel processen bevinden zich qua verwerkingstijd tussen beiden. Om een duidelijk onderscheid te maken, noemen we processen enkel kortlopend als ze nergens wachten op externe manuele of geautomatiseerde input. Alle andere noemen we langlopend (zelfs als de effectieve doorlooptijd van het proces maar minuten of seconden bedraagt).
Veel administratieve processen evolueren in de richting van volledige automatisatie. Dit door gebruik van automatische integraties tussen systemen, RPA (robotic process automation), Machine Learning en AI (Artificial Intelligence).
Waarom is business proces modellering nuttig?
Een business process model beschrijft expliciet hoe de business werkt of zou moeten gaan werken, en wordt om volgende diverse redenen opgesteld.
- Om structuur en overzicht te vinden in de werking van een business die al geruime tijd routinematig is. In de meeste gevallen voert iedereen zijn of haar uit maar is er weinig overzicht over het grotere geheel en de samenhang.
- Om analyses te kunnen maken - zowel kwalitatief als kwantitatief, met een onderbouwde inschatting van doorlooptijden, bottlenecks, foutgevoelige punten, kosten, flexibiliteit,...
- Om te kunnen automatiseren. Door de business process modellen in een tool te brengen die deze aanstuurt en opvolgt, waar en wanneer nodig menselijke interactie vraagt en surplus rapportering genereert
- Om simulaties te kunnen maken - door bijvoorbeeld te kijken hoe werk al dan niet herverdeeld of toegewezen kan worden, activiteiten in andere volgorde te plaatsen en te kijken welke positieve of negatieve impact dit heeft.
- Om gericht opleiding en training te kunnen geven rond de manier waarop er gewerkt wordt.
- Om compliancy met regulering of standaarden te kunnen nagaan.
- Om wijzigingen te kunnen plannen en beheren - als je van gedocumenteerde as-is processen gaat overstappen naar nieuw uitgetekende to-be processen kan je de gap daartussen vlot identificeren én nodige acties ondernemen om een gecontroleerde transitie te maken.
Je kan aan elk proces een procesbeheerder (process owner) toewijzen, dit is iemand die verantwoordelijk is om de kennis en documentatie rond het proces te onderhouden, alsook de toepassing ervan én de eventuele wijzigingen eraan te beheren. Dit schept duidelijkheid over wie beslissingen kan/mag nemen over bepaalde processen en de manier waarop die al dan niet door tooling en software ondersteund kunnen worden. Belangrijk is dat dit, zelfs als er uiteindelijk automatisatie van de processen gerealiseerd wordt, vanuit business kan gebeuren en dus geenszins een louter IT-technische taak is.
Vanuit business standpunt is het logisch verantwoordelijkheden per proces in te delen. Niemand is bijvoorbeeld verantwoordelijk voor een "klant" in z'n geheel. Alle medewerkers, gaande van sales over servicedesk tot boekhouding komen allicht in aanraking met een klant, maar het "customer onboarding" proces of het "client service feedback" proces is anderzijds duidelijk toewijsbaar. Het geeft de stappen weer die doorlopen worden alvorens vooraleer producten of diensten worden geleverd.
Zo'n proces kan maar hoeft niet geautomatiseerd te zijn, al vind je in de realiteit vaak processen die een mix bevatten van beide. Zelfs als een business proces bestaat uit manuele stappen, is het meer dan nuttig om deze te documenteren. Niet alleen wordt het makkelijk zo om nieuwe mensen op te leiden, compliancy met bepaalde regelgeving of normen na te gaan, maar kan men op zoek gaan naar optimalisaties in de werkwijze en mogelijke automatisaties van bepaalde stappen in het proces doorvoeren.
Een gemodelleerd proces laat toe om kwantitatieve analyse toe te passen. Wanneer je gaat meten wat de doorlooptijd, wachttijden, typische fouten, kosten bij elke stap zijn, leg je de basis voor performantie-monitoring en -optimalisatie. Je kan gericht op zoek naar acties die een lagere kost, snellere doorlooptijd, een kleiner aantal fouten kunnen opleveren.
Een BPM Engine laat toe om processen te gaan automatiseren en daarop te gaan rapporteren, zodat het beheren van business processen door een softwarepakket ondersteund kan worden.
Hoe stel je een business proces model op?
De vorm waarin een business process onderhouden wordt is meestal een BPMN Schema (BPMN 2.0 of "Business Process Model and Notation" van OMG is de gangbare standaard hiervoor).
Naast dit proces-model hou je daarnaast best een overzichtelijke vorm van context (meta-data) bij, zoals de naam van het process, de process owner, start- en eind-punten, e.d.
Processen onderling zijn typisch hiërarchisch gestructureerd, met high-level processen (offerte-tot-verkoop, productie-tot-levering, enz...) bovenaan, en gedetailleerde processen (b2b-offertering, afspraak-inregeling, ...) daaronder. Een dergelijk proces architectuur geeft je een hiërarchisch overzicht van je processen.
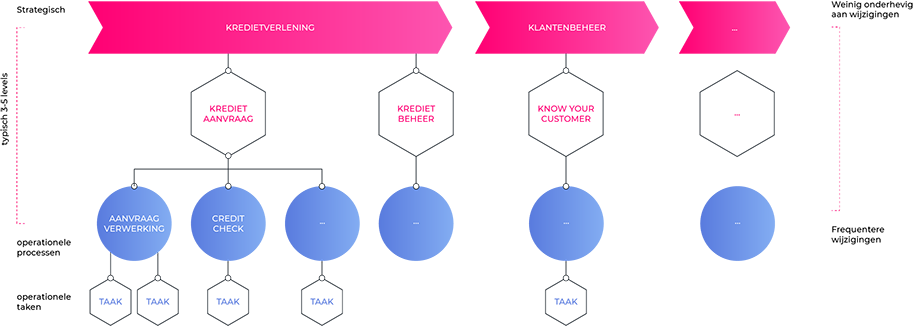
Proces-identificatie is de manier waarop je processen bepaalt én vormgeeft. Vaak sta je voor de keuze om dingen in één groot proces onder te brengen, al dan niet om aparte kleinere processen te benoemen,...
Dit is uiteraard geen exacte wetenschap. Het identificeren en modelleren van specifieke processen kan op vele manieren correct gebeuren. De kunst? Een manier vinden die op maat van jouw situatie werkt.
Meestal ga je op een van volgende manieren te werk, of hanteer je een combinatie van enkele technieken:
- Bottom-up.
Je lijst alle activiteiten die in je business gebeuren op, en zet deze tegenover elkaar en tegenover gelijkaardige gebeurtenissen. Zo breng je deze dan in proces-structuren.
Dit is een techniek die voor de meeste betrokkenen natuurlijk en haalbaar aanvoelt, omdat ze vertrekt vanuit de dagdagelijkse realiteit van activiteiten. - Top-down.
Hierbij vertrek je van een aantal high level processen (verkoop, levering, cash collection, ...) en verfijn je deze stapsgewijs tot je atomaire activiteiten (acties die in één stap op één moment en één plaats kunnen uitgevoerd worden) vast kan leggen. Deze techniek is relevant wanneer je een accuraat inzicht hebt in de procesarchitectuur vanuit een eerdere proces-oefening. Evengoed voor wanneer je aan de slag gaat met standaard proces-modellen voor een bepaalde business of sector, en deze als leidraad neemt om de oefening te sturen. - Process mining.
Op basis van de output van applicaties en tools, spoor je processen (deels) automatisch op. Op basis van historische output en loginformatie, zet je data mining technieken in om zo sequenties en het parallellisme tussen de activiteiten in kaart te brengen.
BPM Engines en software engineering
Naast de "klassieke" toepassing van BPM Engines, het automatiseren en beheren van business processen, zijn er ook heel wat andere nuttige manieren om deze tools in te zetten. Hier enkele voorbeelden op een rijtje.
Microservices Orchestratie
Al jaren is het een tendens om binnen software engineering de software fijnmaziger te maken. Hier doelen we op een microservices architectuur met kleine en zo onafhankelijk mogelijke componenten die samen één grote oplossing vormen. Op deze manier wordt het mogelijk om elk van die componenten een eigen levenscyclus te geven, apart uit te rollen, up te daten of toe te wijzen aan een ontwikkelteam.
Wanneer je een microservices architectuur toepast, word je al snel geconfronteerd met de vraag hoe de interactie tussen de verschillende kleine services best wordt opgezet. Vermijd een wirwar van onderling afhankelijke componenten die op onvoorspelbare momenten interageren, dit bemoeilijkt sowieso het doel om overzicht te behouden. Focus op duidelijke inrichting en structuur. De exacte samenhang tussen deze interacties of de "flow" tussen deze componenten zijn namelijk een belangrijk deel van de werking van je systeem.
Interacties tussen software componenten kunnen in grote lijnen twee vormen aannemen:
- Het aanroepen van een component vanuit een andere op het moment dat er iets dient te gebeuren, vaak via een service call op een API. In een typische microservices architectuur wordt ervoor gezorgd dat de afhankelijkheid tussen de twee componenten zo beperkt mogelijk is. In praktijk "weet" de aanroepende component van het bestaan van een andere component die een bepaald service contract aanbiedt. Het localiseren en aanroepen van de service, wordt buiten de applicatie-code om afgehandeld. Een architectuur die hiervoor voorzien is, maakt typerend gebruik van een service registry, API management, service routing...
- Het produceren en consumeren van events of berichten. Hierbij kunnen andere componenten reageren op de gebeurtenissen die zich voordoen, zonder dat er een specifieke afhankelijkheid hoeft te zijn van het component dat de gebeurtenis produceert of meldt, en de componenten die hierop reageren of deze consumeren.
Een architectuur die dit principe primair gebruikt wordt een event-driven architecture genoemd.
In beide modellen - die je trouwens vaak gecombineerd aantreft in een architectuur, is de kern van de zaak om het overzicht te behouden. Wat gebeurt er in welke volgorde, welke service roept welke andere aan, enz...?
Een BPM Engine door middel van procesmodellen kan ervoor zorgen dat de verschillende services onafhankelijk van elkaar blijven, je rijgt hun functionaliteit aan elkaar vanuit een business process dat bepaalt wat er wanneer gebeurt. Verder kan een Message Start Event een perfecte invulling zijn van het event-driven concept in de architectuur.
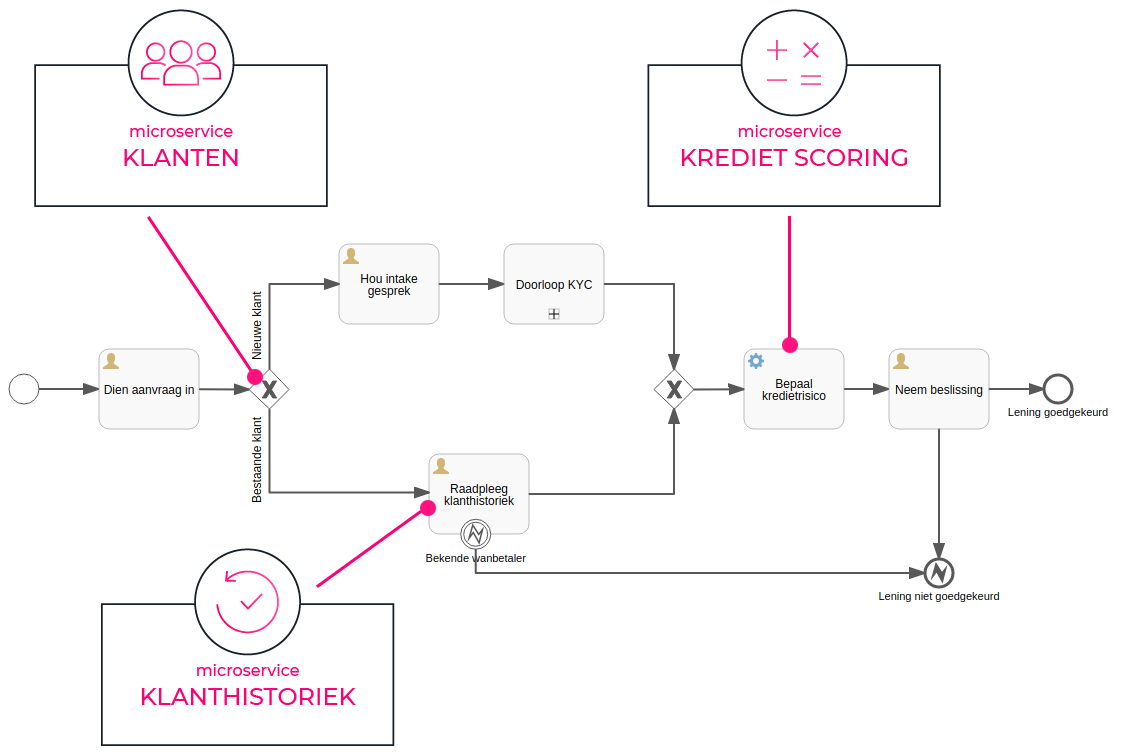
Daarnaast biedt deze aanpak een elegante oplossing voor een aantal complexere vraagstukken die opduiken in een microservices architectuur. Binnen fijnmazige software worden functionaliteiten namelijk in verschillende componenten ondergebracht, en kan de klassieke transactie niet zorgen voor de nodige ACID (Atomic, Consistent, Independent en Durable) eigenschappen. Rollbacks van reeds uitgevoerde acties kunnen perfect mappen op cancel en compensation events uit de BPMN standaard.
Een fijn neveneffect van het inrichten van een BPM tool als orchestratie bovenop microservices, is dat de samenhang van de componenten ook rechtstreeks aanleiding geeft tot een inzichtelijk real-time beeld van de status van elke verwerking.
In dit scenario zijn de processen redelijk technisch, en ga je dus best gelaagd te werk. Je voorziet effectieve aanroepen van je diverse microservices enkel op het laagste niveau in je proces-architectuur, en behoudt de bovenliggende lagen voor meer high-level en business-georiënteerde processen. De inzichtelijkheid die je technisch realiseert, moet uiteraard herkenbaar blijven voor business, niet enkel voor de IT'ers die de integratie realiseren.
Elke moderne BPM Engine kan op basis van business proces modellering dienen als orchestratielaag voor een microservices architectuur.
Natuurlijk zijn er ook specifieke oplossingen gericht op microservices orchestratie. Bijvoorbeeld zeebe.io, dat een aangepaste versie van de Camunda BPM engine voorziet onafhankelijk van een centrale database, en dus zo geschikt wordt voor het verwerken van zeer hoge volumes én een single-point-of-failure in de architectuur vermijdt.
Snelle end-to-end prototyping
Het bouwen van een complexe toepassing gebeurt tegenwoordig meestal op een iteratieve manier. Daarbij zijn Scrum en Agile methodologieën ondertussen in vele organisaties bekend en in praktijk toegepast. Dit neemt echter niet weg dat de echte business validatie vaak pas relatief laat in het project mogelijk wordt gemaakt. Om end-to-end processen effectief te doorlopen en te valideren, is er meestal een stevig stuk van de geplande realisaties nodig. Onder andere de integratie tussen verschillende systeemonderdelen, de opzet van user interfaces om verschillende acties en input te verwerken, enz...
Nochtans is deze end-to-end validatie cruciaal. Het brengt subtiele onvolkomenheden of issues in beeld die terug te leiden zijn naar een fout begrip van hoe de business werkt.
De toepassing van een BPM Engine kan zeer waardevol zijn doordat je makkelijk end-to-end prototyping kan realiseren, wat potentiële issues in een vroeg stadium kan ondervangen.
Door enerzijds uitgetekende business processen in een BPM Engine te automatiseren, kan je de interactie-punten met andere systemen en menselijke gebruikers beperkt realiseren. Hierdoor kan je wellicht in vroege projectfase end-to-end flows doorlopen, en zo de systeem werking op een pragmatische manier af toetsen. Dit met oog op business en de toekomstige gebruikers.
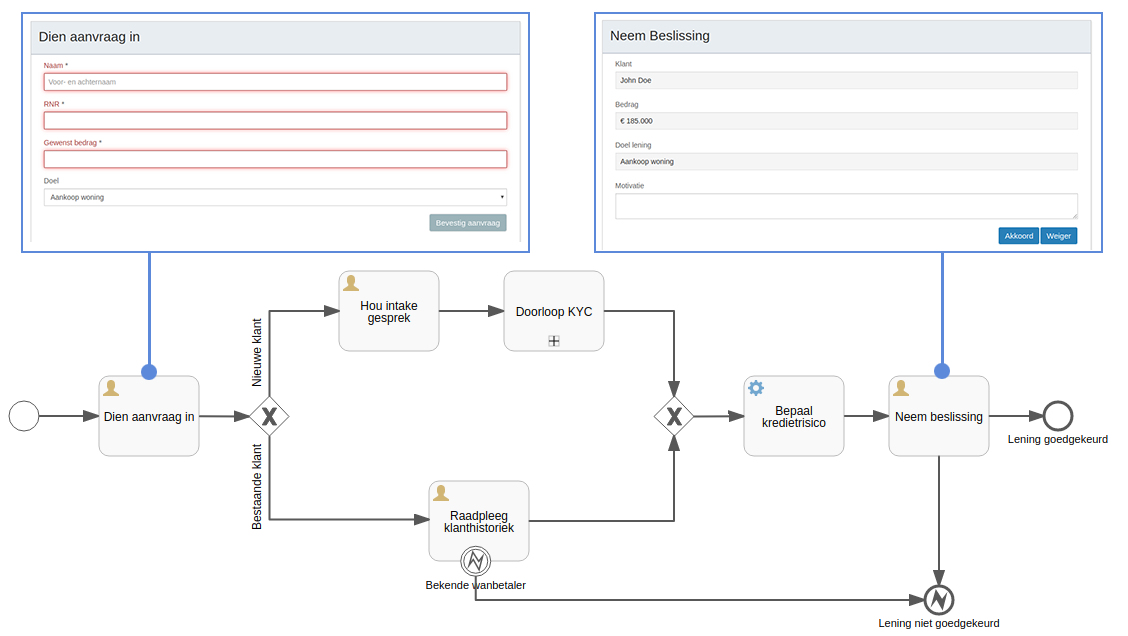
Een typische BPM Engine bevat tooling om snel formulier-gebaseerde input te capteren en tooling die taken aanbiedt aan gebruikers in een generieke taken-toepassing. Met een minimum aan inlevingsvermogen kan je op basis hiervan aan de slag voor end-to-end testing.
Alle touchpoints zijn dan vervangen door een tijdelijke implementatie (typisch ruwe invoer, zonder al te veel validatie en gebruiksvriendelijkheid) maar laten toe om volledige testcases "door het systeem te halen" om fouten of ontbrekende cases te identificeren.
Processen vormen op dat moment een gemeenschappelijke taal tussen business en IT en zijn een rijke aanvulling op de klassieke schermschetsen (mock-ups) en user interface designs die vaak gebruikt worden.
In praktijk betekent dit dat er bij opstart een prematuur, maar volledige, oplossing in basisvorm staat, wat een betere stip op de horizon plaatst dan 'in development'- status. Deze aanpak geeft duidelijk weer welke onderdelen van de processen eerst moeten worden uitgewerkt, én biedt een werkkader om verdere uitdieping van elke activiteit binnen zo'n proces te plannen en budgetteren.
Process Intelligence
Eén van de grote voordelen van een business proces dat geautomatiseerd wordt in een BPM Engine, is de gedetailleerde logging rond elke stap. Voor elke procesinstantie wordt in detail bijgehouden welk stapje wanneer genomen wordt, wat de verwerkingstijd en het uiteindelijke resultaat is. De informatie over de proces-instantie bevat ook alle procesvariabelen - deze worden gelogd samen met de exacte omstandigheden van de uitvoering (wie, wat, wanneer).
Naast een kruimelspoor van operationele activiteiten om op te zoeken wanneer er wat gebeurde, kan deze informatie aangewend worden om een stukje intelligentie te voorzien door deze in een Machine Learning model te verwerken. Op basis van de huidige status van het proces en de bijhorende historiek, kan je volgende zaken gaan voorspellen:
- Verwachte doorlooptijd en uiteindelijke eindmoment van het proces
Bijvoorbeeld: de gebruiker op de hoogte brengen (user delightment) van de wachttijd en omstandigheden."We verwachten binnen een 3-tal dagen antwoord". Deze informatie wordt ingegeven door statistieken omtrent vergelijkbare processen uit het verleden, en niet op basis van business rules. Bepalende factoren hangen dan enkel van de situatie af en worden bepaald op basis van de historische gegevens. Zo hoef je geen rekening meer te houden met assumpties dat een proces dat op maandagmorgen start een kortere verwachte doorlooptijd heeft dan eentje dat op vrijdagnamiddag wordt aangevat. - Verwachte eindstatus van het proces
Hoeveel processen met een vergelijkbare historiek zijn positief of negatief afgelopen, of in een specifieke eindstatus gekomen?
Met deze informatie zou je aan de slag kunnen gaan om taken die de meeste kans op een positief resultaat, prioriteit te geven. Hallo operational excellence!
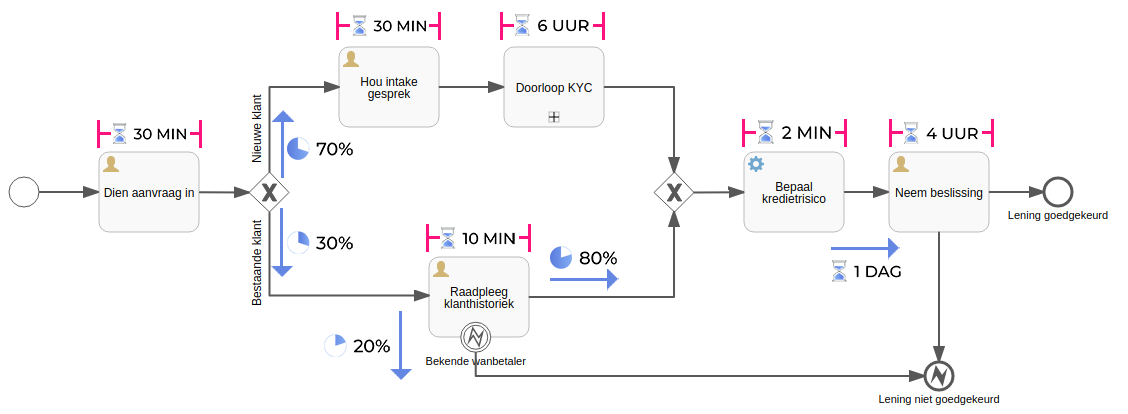
Als je een voldoende groot volume aan procesdata hebt (en voldoende statistisch relevant) dan kan je op een evidente en kost-efficiënte manier een Artificial Intelligence aspect toevoegen aan je systeem. De tabulaire vorm waarin data aan een machine learning algoritme wordt aangeboden, is meestal makkelijk te extraheren uit de database die onder een BPM Engine zit. Dit soort technieken begint ook vaker out-of-the-box te verschijnen in BPM tools. Waar deze nog niet bestaan kunnen ze, zonder te complexe stappen, alsnog voorzien worden.
Zeer interessant is ook het inzicht in wat de meest bepalende indicatoren zijn voor een succesvolle of snelle verwerking van een proces. Je leert daarnaast bij over welke factoren problematische situaties doen vermoeden (de meest significante "features" in een machine learning model).
Adaptive Case Management
Naast de BPMN-processen ondersteunen de meeste BPM tools ook minder bekende CMMN of Case Management modellerings standaard.
Case Management wordt gebruikt in situaties waar activiteiten aan een case of dossier gerelateerd zijn, maar niet altijd een duidelijke sequentie in de activiteiten zit. Waar een business proces (BPMN) uitgaat van een zekere logische volgorde van activiteiten - sommige weliswaar voorwaardelijk, parallel aan elkaar of repetitief - gaat een case model (CMMN) uit van een aantal taken die op een gegeven moment mogelijk, verplicht of onmogelijk worden, en een set van voorwaarden waaraan voldaan moet zijn om de case terug af te sluiten.
Alhoewel de CMMN standaard er op het eerste zich even bevattelijk uitziet als een BPMN proces, is in de praktijk de correcte modellering een stukje moeilijker. De interpretatie voor niet-ingewijden is, in tegenstelling tot bij business proces, niet evident.
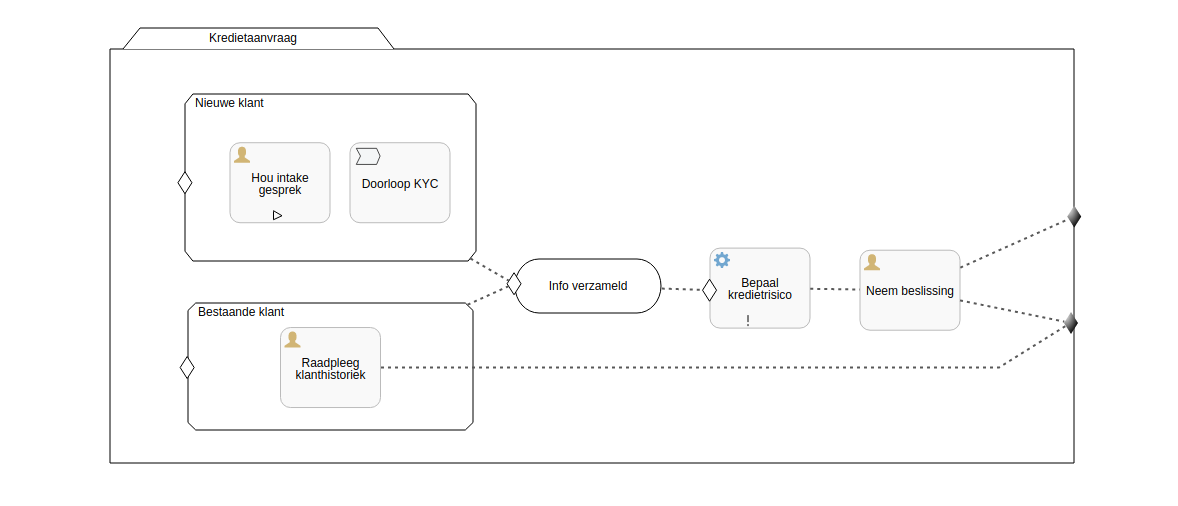
Belangrijk om weten is dat alles wat je in BPMN kan modelleren, ook in CMMN kan weergegeven worden en vice versa, maar wat triviaal is in het ene model, is vaak zeer complex in het andere model.
- Een business proces dat zeer veel activiteiten parallel en optioneel maakt, betekent meestal dat je beter een case-model zou hanteren
- Een case-model waar je veel sequentie in stopt, is mogelijk vlotter te modelleren als een proces.
BPMN en CMMN gebruik je meestal ook samen. Zo kan één activiteit in een business proces dienen om een case te openen en al dan niet te wachten tot deze afgehandeld is om verder te kunnen in het proces, of kan in de context van een case op een gegeven ogenblik een business proces opgestart worden. Hier ontstaat dan weer de keuze om al dan niet verplicht te wachten tot het proces afloopt om de case te kunnen sluiten.
Alhoewel case modellering misschien minder evident is dan business proces modellering, is het concept van een case een stukje tastbaarder voor business specialisten. Indien je bottom-up gaat modelleren en dus eerst specifieke activiteiten gaat oplijsten kan je nadien nog beslissen of je deze best in een case model dan wel in een procesmodel stopt. Sommige BPM Engines durven een case model intern al eens om te zetten naar een procesmodel, andere tools zoals Flowable hebben er een specifieke case-model-engine voor.
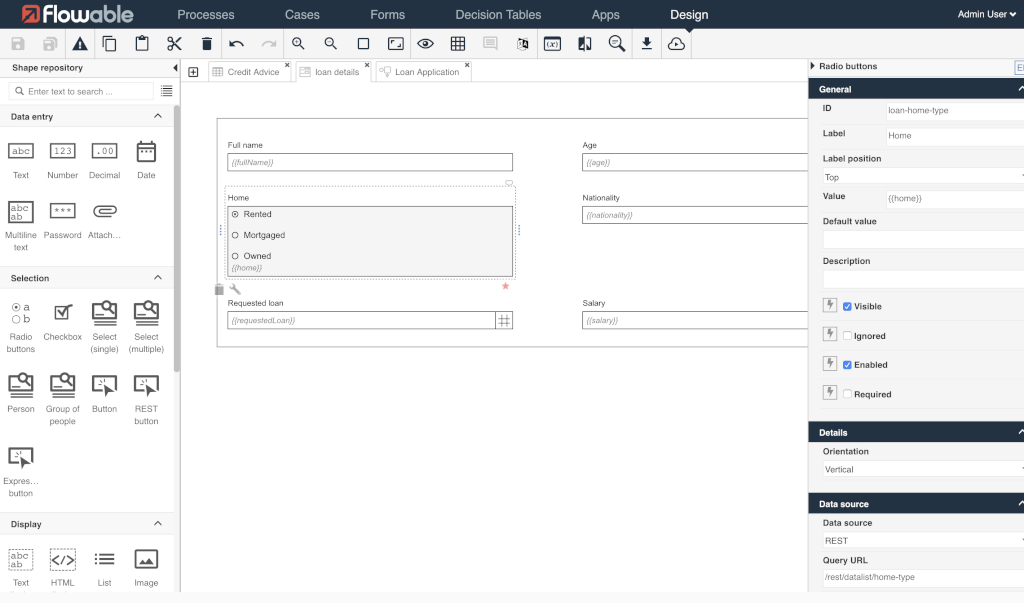
Dynamische formulieren
Veel BPM-engines hebben een ingebouwde formulieren-oplossing. Deze kan je gebruiken om invoer van gebruikers te capteren. Deze formulieren vind je meestal aan de start van een proces, waar ze als input dienen om het proces te initiëren. Denk aan het stereotiepe lening-aanvraag model dat vaak gebruikt wordt in demo's van dit soort tools. Daarnaast vind je ze evenals terug in elke stap waar een "user task" moet uitgevoerd worden, waar ze als een eenvoudig configureerbare user interface zowel informatie tonen als opvragen bij de gebruiker.
Deze mogelijkheid kan ook zeer handig zijn om variabele invoer op te vragen, deze te routeren naar het juiste pad of de juiste persoon, en de verkregen informatie in beslissingstabellen (DMN) te gebruiken. Afhankelijk van de situatie kan je op die manier bijkomende informatie van dezelfde of een andere gebruiker gaan opvragen, integratie met andere systemen opzetten, mails sturen, documenten genereren, enz...
Logging van activiteiten ("wie voerde wanneer wat in?") komt uiteraard automatisch mee met de process logging.
Een aantal BPM tools zijn diep geïntegreerd met een content- of document-management oplossing, waar ze heel wat meta-data capteren over beheerde items (documenten, foto's, ...) die op basis van deze meta-data de nodige goedkeuringen, omzetting, verwerking, e.d. doormaken. Dezelfde techniek kan rond eender welk stukje gecapteerde informatie gehanteerd worden, dus indien je project-vereisten rond dynamische formulieren hebt is een BPM-engine zeker iets om over na te denken!
Vaak is een BPM tool voorzien van een eenvoudige formulieren-editor die zonder programmeren (low-code of no-code techniek) toelaat om formulieren te ontwerpen, wat snelle prototyping toelaat en de nodige doorlooptijd en budget beperkt.
Process Automatisatie en Optimalisatie
Naast al deze specifieke toepassingen voor BPM Engines kan je uiteraard ook nog steeds veel meerwaarde halen uit hun klassieke toepassing: het automatiseren van business processen.
Naar automatisatie toe, kan je vlot een mix van manuele en geautomatiseerde taken voorzien, alsook externe systemen op de nodige momenten bevragen of opstarten. Eén belangrijk punt in verband met automatisatie dat je niet over het hoofd mag zien, is de taakverdeling voor alle User tasks.
Door een goede configuratie van de tool kan je heel wat operationele optimalisaties doen:
- aanbieden van taken naar een team toe in plaats van naar specifieke mensen
- routeren van taken naar de meest logische persoon of groep
- organiseren van samenwerking in een team door taken te claimen, prioriteiten en reminders te zetten, enz...
- tijdelijk delegeren van taken naar andere mensen
- vrijhouden van capaciteit van specifieke kennis voor taken waarvoor deze echt nodig is
- enzovoort.
Geautomatiseerde processen zijn makkelijk te monitoren. Hoeveel processen lopen er, wat is de gemiddelde duurtijd, welke processen vallen buiten de verwachte doorlooptijden, welke lopen vast op problemen, enz...
Al deze zaken zijn even goed mogelijk zonder BPM engine maar kosten dan sowieso wel extra tijd en budget voor realisatie en testing.
Gebaseerd op deze informatie kan je door middel van analyse beginnen kijken naar mogelijke optimalisaties. Denk aan procesaanpassingen, zoals het uitstellen van taken die uitgevoerd worden waarna het proces alsnog negatief beëindigd wordt. Met dit soort optimalisaties vermijd je overbodig werk. Daarnaast kan je experimenteren met bijvoorbeeld A/B testing op business processen, zo kan je de vlotst werkende variant, op een logische en makkelijke manier selecteren.
Voordelen van BPM-gebaseerde oplossingen
Business process modelling kan je inzetten op verschillende niveau's:
- Beschrijvend (haalbaar voor iedereen)
In deze vorm hanteer je BPMN constructies om bevattelijk over processen te communiceren en ze te documenteren. Vaak daal je niet al te diep af naar specifieke details en blijven de processen eerder high-level. Ook syntactisch correcte modellering en het volledig voorzien van alle uitzonderlijke scenario's wordt vaak vermeden om de schema's bevattelijk te houden. De meeste BPM modeling tools laten ook toe om losjes om te springen met de syntactische regels van BPMN, net om ad-hoc beschrijvende modellering toe te laten. - Analytisch (vereist een opgeleide business analyst of modeler)
Als je naar een software-specificatie toe werkt of bijvoorbeeld compliancy met bepaalde regels wil valideren, zal je gedetailleerdere informatie over processen nodig hebben, je gaat deze dieper analyseren en de nodige aandacht geven aan syntactische correctheid en volledigheid van de modellering. Tools komen vaak een heel eind tegemoet in het valideren van modellen. - Uitvoerbaar (impliceert betrokkenheid van IT of een BPM developer)
Wil je je processen in een BPM Engine gaan automatiseren, dan zijn er heel wat stukjes modellering en configuratie die je aan de modellen moet toevoegen om deze uitvoerbaar te maken. Heel wat praktische vragen dienen hier een antwoord te krijgen: welke gebruikers of groepen krijgen welke User Tasks toegewezen? Welke delen van het proces lopen asynchroon, en voor welke verwachten we bij aanroep een directe verwerking en aanpassing?
Welk niveau van procesmodellering je ook hanteert, door vanuit processen te denken, bouw je inherent een aantal voordelen op - we geven hier de belangrijkste aan.
Vlotte alignering van Business en ITEen niet te onderschatten voordeel van een benadering aan de hand van business processen is de alignering tussen Business en IT. Business processen kunnen als het ware een lingua franca vormen die het mensen met diverse achtergrond toelaat om helder te communiceren over werkstromen en hoe die verlopen of zouden moeten verlopen.
Om een groter geheel in logische kleinere behapbare delen op te delen, denkt business vaak vanuit processen, terwijl IT snel teruggrijpt naar informatie-structuren.
Deze mismatch is zeker één van de redenen waarom het niet altijd makkelijk is om een scope voor een software ontwikkeling juist af te bakenen.
Een software beschrijving op basis van business processen en BPMN zorgt voor een inzichtelijk systeem, dat geen blackbox is voor business - met herkenbare concepten ipv technische details. Het laat ook toe om aan alle stakeholders meer of minder detail te tonen, maar toch hetzelfde model te blijven hanteren. Een high-level beschrijvend business proces hoeft geen onderscheid te maken tussen een Service Task en een User Task of de juiste semantiek rond Messages en Signalen te hanteren. Deze details kunnen, bijvoorbeeld ten behoeve van een automatisering in een BPM tool, wel vlot toegevoegd worden.
Processen gaan ook typisch over departementen en functies heen. Een order proces begint bijvoorbeeld op de sales afdeling, maar passeert de boekhouding en het warehouse. Om één business verantwoordelijke te vinden voor een deel van een volledige scope zal je dus eerder per proces bij een proces owner uitkomen. Een proces owner voor het "order proces" is allicht te vinden, iemand die alle kennis en beslissingen centraliseert rond "orders" niet.
| FUNCTIES | ||||||
| Klant | FrontOffice | BackOffice | Boekhouding | Legal | ||
|---|---|---|---|---|---|---|
| PROCESSEN | Krediet aanvraag | X | ||||
| Kredit beoordeling | X | |||||
| Krediet beheer | X | X | ||||
| Know Your Customer | X | X | ||||
Een proces gebaseerde aanpak legt de basis voor een vlottere alignering tussen IT en Business en een hogere en diepgaandere betrokkenheid van business in software ontwikkelingsprojecten. Een onderwerp dat we met Process Driven Architectures nog verder verkennen
Basis voor mens-machine samenwerking
Software bevat typisch een combinatie van functionaliteiten die autonoom (geautomatiseerd) verlopen en activiteiten die menselijke input of beslissingen vereisen. BPMN Processen bevatten deze nuance al zeer expliciet, door een onderscheid te maken tussen:
- Manual Tasks - taken die manueel moeten afgehandeld worden maar niet door software ondersteund worden.
- User Tasks - taken die manueel moeten afgehandeld worden en waarvoor applicatie-functionaliteiten voorzien zijn.
- Service Tasks - taken die geautomatiseerd zijn door scripting, of door integratie met een extern systeem, en geen menselijke interactie vereisen.
Op deze manier faciliteren processen in een BPM Engine een vlotte integratie tussen geautomatiseerde en menselijke activiteiten. Informatie uit verschillende systemen én informatie afkomstig van gebruikers komt samen in procesmodellen en kan van daaruit vlot geïntegreerd en ontsloten worden.
De generieke takenlijst-functionaliteit die in de meeste BPM Engines aangeboden wordt, biedt een duidelijk actionable overzicht van alle taken waarop moet gewerkt worden. Ook automatische fallback scenario's bij te lange wachttijden, escalaties, e.d. vullen deze functionaliteiten verder aan. Vaak is deze standaard takenlijst-functionaliteit een goed startpunt om van te vertrekken, maar worden specifieke taken later, via meer geschikte kanalen die meer context bieden (een mobile app, een webportaal, ...), aan gebruikers aangeboden.
Als dezelfde end-to-end processen via klassieke software benadering worden gerealiseerd, moet er veelal integratie tussen deze systemen en een mapping van datastructuren opgezet worden. Een BPMN model ondersteunt dit door alle informatie die aan een end-to-end proces gerelateerd is, centraal te verzamelen als procesvariabelen.
De verdeling tussen manuele en geautomatiseerde activiteiten is geen statisch gegeven. Dikwijls is de ambitie om manuele taken terug te dringen en deze te vervangen door automatisaties of integraties met externe toepassingen, beslissingen te vervangen door artificiële intelligentie of expert-systemen, enz... Het resultaat is een snellere doorlooptijd, een lagere operationele kost en een kleinere foutmarge.
Ook hier komt een BPM-gebaseerd systeem sterk in tegemoet: een task van een User Task naar een Service Task wijzigen, verandert geenszins het business proces op zich, en de ontkoppeling tussen verschillende activiteiten met duidelijke in- en uit-gaande procesvariabelen, maakt het geïsoleerd vervangen van één activiteit door een automatisatie meestal vlot mogelijk.
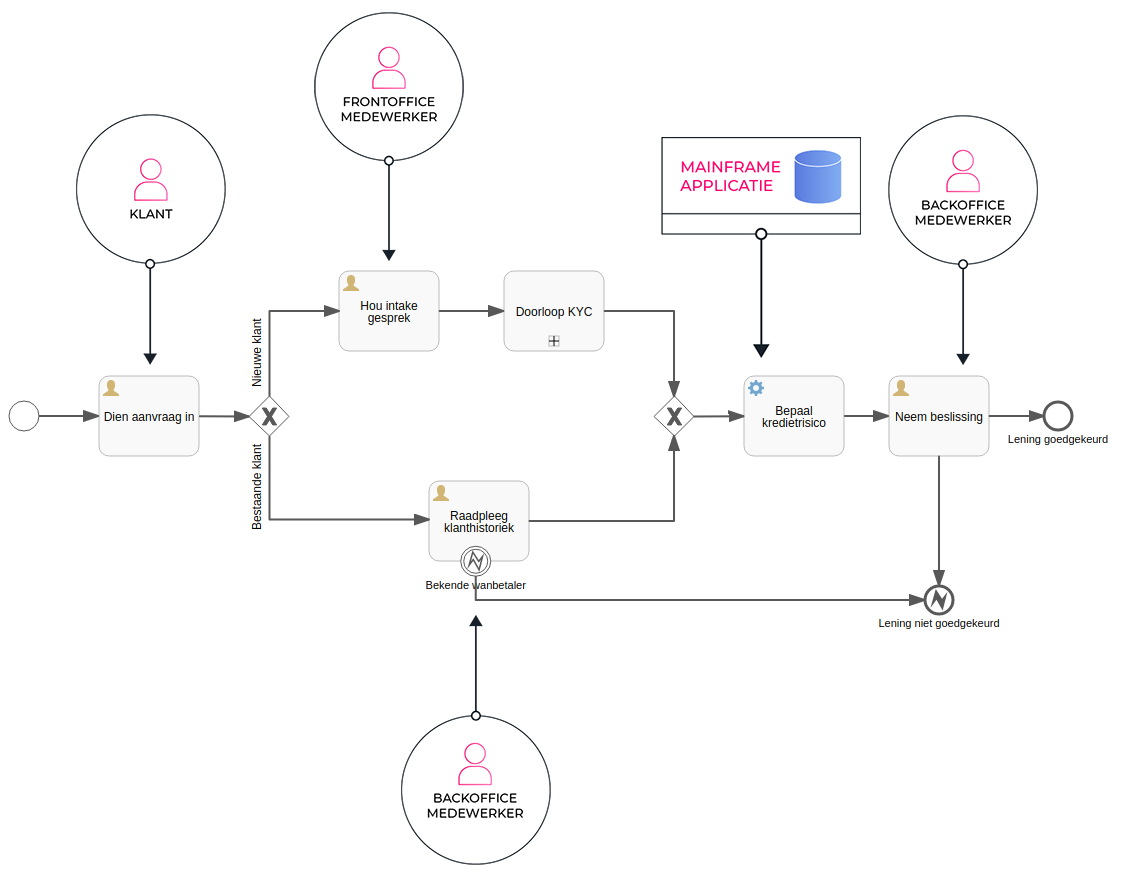
Ook in sterk geautomatiseerde systemen is er vaak nood aan ad-hoc menselijke interventies: denk maar aan content reviewing, waar mensen beoordelen of specifieke content al dan niet op een platform gepubliceerd mag worden, of validatie van geautomatiseerde beslissingen, waarbij al steekproef menselijke beoordeling de kwaliteit van de geautomatiseerde beslissingen blijven monitoren. Ook op deze aspecten is het op de juiste plaats inpikken in de processen, meten wat de kwantiteit en kwaliteit van de cases is en in functie daarvan ingrijpen.
We beschreven al dat business processen dwars door afdelingen en functies snijden. Dit betekent ook meteen dat business processen vaak over applicaties heen een rol spelen.
Activiteiten in een business proces vertalen zich vaak in specifieke acties in een software systeem. Wanneer een boekhouding een specifiek softwarepakket gebruikt, zal een proces rond het verwerken van onkosten-nota's op een gegeven moment allicht een taak bevatten om de nodige boekingen te doen. Of deze manueel gebeuren of automatisch gecreëerd worden is ondergeschikt aan het feit dat dit een fundamentele stap in het proces is, en op voorafgaande andere activiteiten volgt.
Mensen die een manuele taak dienen uit te voeren, moeten ongetwijfeld de nodige informatie ter beschikking hebben die een stuk verder gaat dan wat er in de procesvariabelen in functie van de processturing vervat zit. Vaak betekent dit dan een opzoeking van informatie in een extern systeem. Een manuele taak "Pick Order" in een orderverwerkingsproces zal een duidelijk overzicht van de nodige items, locatie van de stock, e.d. moeten ophalen uit een warehouse management system om informatie aan de gebruiker aan te leveren zodat die de taak snel en accuraat kan uitvoeren.
De praktische invulling van activiteiten is vaak een interactie op of met een extern systeem. Dat maakt dat business processen een heldere informatiebron rond alle bestaande of mogelijke integratie-punten vormen.
Integraties zijn vaak een complex gegeven, aangezien IT systemen eigen informatiemodellen en dataformaten bevatten die op elkaar gemapt moeten worden, en verschillende communicatieprotocollen moeten vertaald geraken.
BPM Engines voorzien een elegante manier om de functionele aspecten (welk systeem, wanneer, welke interactie) in beeld te brengen binnen een procesmodel, maar alle verregaandere technische details achterwege te laten. Een Service Task kan perfect een stukje programmatuur bevatten die de effectieve integratie abstraheert.
Verder voorziet een procesmodel mogelijkheden om om te gaan met asynchrone integraties (messaging), transactionaliteit (compensating activities), foutafhandeling en retries e.d.
Voortbouwend op de integratie-insteek, biedt het gebruik van een BPM Engine ook garanties naar een zekere ontkoppeling tussen de verschillende componenten. Aangezien elke activiteit in het proces als het ware een geïsoleerde proxy biedt naar het achterliggende systeem, die enkel door de aanroepende parameters (typisch procesvariabelen) met de rest van het proces gekoppeld is, garandeert dit ook ineens een onafhankelijkheid van dit systeem van de andere betrokken systemen.
Terwijl een BPM Engine zeker geen integratie-platform is, levert het dus vaak wel zeer nuttige voorzieningen aan om de basis voor beheersbare integraties te realiseren.
Ook aan de gebruikerskant is het redelijk evident om bovenop een procesmodel een integratie-laag op basis van een API te bouwen die gebruikersapplicaties toelaat om in te grijpen in lopende processen, nodige invoer en beslissingen aan te leveren. Alle User Tasks kunnen vlot geïntegreerd worden in specifieke toepassingen waar gebruikers er in de meest logische context aan kunnen werken. Een aanpak waarbij de BPM Engine in feite wordt ingepakt en ontsloten door een REST API naar andere applicaties toe, is met de moderne lightweight engines een veel voorkomend patroon.
Decision Management en Business RulesEen business proces definiëert hoe je gericht naar een einddoel toewerkt, maar gaandeweg moeten ook een aantal beslissingen genomen worden. Telkens als je je proces de ene of ander richting uit stuurt, dient er een evaluatie van de situatie te gebeuren. Vanuit business bekeken zijn dit vaak beslissingen die gebaseerd worden op specifieke Business Rules.
Een klein voorbeeld: stel dat je in je bestelproces de volgende beslissingen wil verwerken: klanten die voor de eerste keer bestellen krijgen een cadeautje bij hun eerste levering en trouwe klanten (op basis van aankoophistoriek Silver of Gold Customers) krijgen een korting van respectievelijk 3% en 5%.
De vraag is dan hoe je dit best modelleert alsook hoe je dit implementeert (automatiseert) zodat de beslissing automatisch kan gemaakt worden.
Een rechttoe-rechtaan modellering kan er als volgt uit zien:
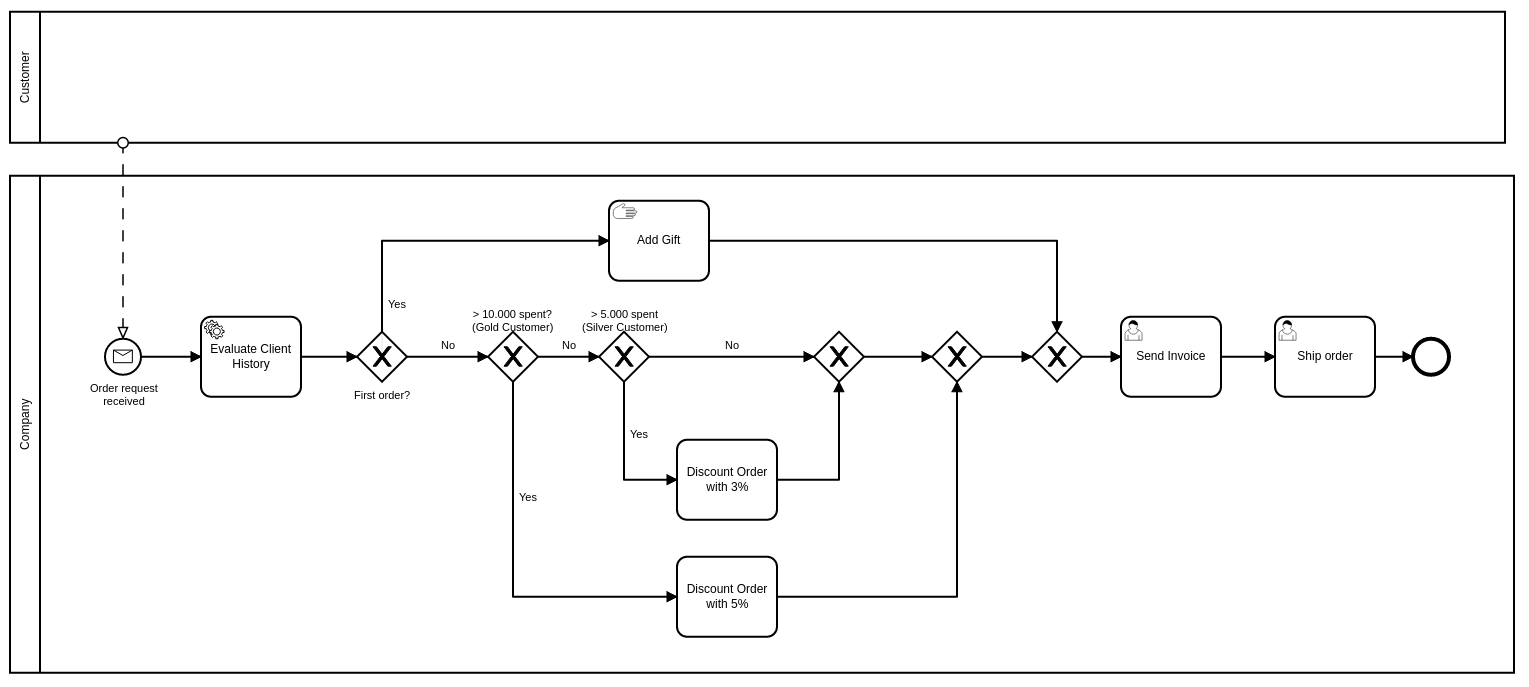
Je voelt meteen aan dat hier een en ander op aan te merken valt:
- Het business proces wordt al snel heel complex. Als je dit met business doorloopt krijg je waarschijnlijk al snel de opmerking dat het proces ook vrij technisch is. Dat is op zich geen onterecht opmerking, deze beslissingen hebben eigenlijk geen plaats in het business proces. De controle-structuren van het proces worden immers gebruikt om programma-logica te vervangen.
- Indien de definitie van een Silver Customer, een Gold Customer, of de voorziene kortingspercentages worden aangepast, moet je je business proces aanpassen en een nieuwe versie deployen. Dat is op zich niet logisch aangezien de processtappen en logica niet veranderen. Business Rules wijzigen in principe vaker dan de processen zelf. Een nieuwe versie van het proces moeten publiceren om enkel de wijziging van enkele business rules te realiseren is dan ook niet de meest werkbare techniek.
Door het gebruik van DMN (Decision Model and Notation) kan er gelukkig geoptimaliseerd worden. Door de definitie van het type klant én de bijhorende kortingspercentages in een aparte beslissingstabel (met een aantal business rules) te modelleren, kan je de situatie een stuk duidelijker maken:

En om deze beslissingslogica niet in programmacode om te moeten zetten, laad je ze meteen in de BPM Engine in, en roep je die aan vanuit het verbeterde business proces door middel van een Business Rule Task:
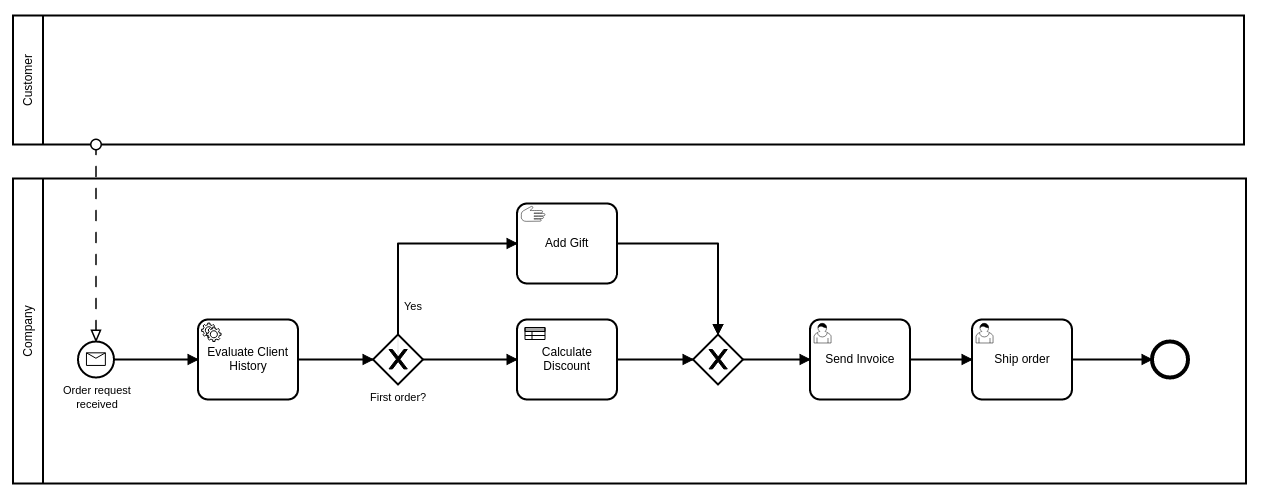
Op deze manier wordt het proces herleid naar waar het echt om draait: we berekenen een korting op basis van de historiek van de klant die het order plaatst, maar de details worden vervat in een set business rules die apart beheerd worden. Indien deze regels wijzigen, hoef je enkel de nieuwe beslissingstabel (DMN) aan te passen terwijl het proces exact hetzelfde blijft.
Dit eenvoudige voorbeeld is makkelijk over te zetten naar complexere beslissingsstructuren, bv met DMN tables die berekeningen uitvoeren (bv: toepasselijk btw percentage bepalen), routering bepalen (bv: wat is de volgende uit te voeren stap), of classificatie toepassen (bv: is deze case als een hoog risico te beschouwen of niet?). Belangrijk is telkens dat het procesmodel gebruikt wordt om te bepalen wat we doen en wanneer, en de beslissingstabel dient om uit te drukken hoe die beslissing vorm krijgt.
Bij het monitoren van processen zal een BPM Engine ook de uitgevoerde beslissingen loggen en ter beschikking stellen. Dit is inclusief de versie van de rules die toegepast werden, de inkomende informatie én de genomen beslissing. Hierdoor wordt het inzicht in hoe we tot een beslissing kwamen heel transparant.
Door deze beslissingstabellen in DMN (Decision Model and Notation) uit te drukken kunnen ze perfect opgesteld worden door of met niet-IT-technische gebruikers. In feite wijken DMN tabellen niet ver af van de zo geliefkoosde Excel-files die vaak gebruikt worden om dergelijke dingen uit te drukken. Daarnaast kunnen ze één-op-één van specificatie naar de engine runtime ingeladen worden, wat betekent dat er geen tijd verloren gaat met het omzetten naar programmacode en het testen hiervan.
Dit zorgt niet alleen voor minder fouten en een kortere doorlooptijd, maar vermijdt ook dat business rules diep in de programmacode van het systeem worden ingebouwd, waardoor onderhoud en wijzigingen moeilijker zouden worden.
Vaak wordt dit aspect van BPM Engines ook gepresenteerd als een mogelijkheid voor business om zelf aanpassingen aan rules aan te brengen, zonder daarvoor langs IT te moeten passeren. Het aanpassen van business rules in DMN modellen is voor veel niet-technische gebruikers zeker mogelijk, maar bedenk dat deze DMN tabellen exact dezelfde functie uitoefenen als een stuk programmatuur in een klassieke applicatie. Geautomatiseerde end-to-end testen zouden de wijziging moeten opmerken en melden dat de gedraging van de applicatie niet meer dezelfde is als voorheen. (Is dit niet het geval dan betekent dit dat er geen degelijke test coverage van het proces met deze beslissing is). Na aanpassing van de testen, waarmee je aangeeft dat de nieuwe berekening inderdaad de gewenste is, is de situatie hersteld. Best worden deze aanpassingen dus mee door je ontwikkelstraat gehaald en passeren ze de nodige quality review. Op welke manieren je BPMN modellen in je ontwikkelstraat kan inpassen lees je in onze blog post daarrond.
Voorbereiding op toepassen van Machine Learning op manuele takenAls je je business processen automatiseert in een BPM Engine, blijven er heel wat manueel af te handelen taken over. Deze komen typisch als een User Task voor in de processen, en worden via een generieke takenlijst-applicatie binnen de Engine of via de integratie met een gebruikersapplicatie (web applicatie, mobile applicatie, ...) aan gebruikers aangeboden.
Vaak gaat het om beoordeling van informatie en het nemen van beslissingen die niet eenvoudig in business rules te vertalen zijn, maar vergen ze een zekere ervaring, inzicht in de materie en soms ook menselijk aanvoelen rond wat er de beste volgende stappen zijn.
Analyse van je processen laat toe om snel in te schatten wat dit operationeel betekent:
- hoeveel van zulke beslissingen worden er dagelijks, wekelijks, jaarlijks genomen?
- hoeveel tijd wordt hier gemiddeld aan gespendeerd?
- wat is de kost van deze tijd - gaat het om schaarse specialistische kennis, of is het eerder generieke materie?
- wat is de typische wachttijd alvorens een gebruiker ze oppikt en afwerkt, en wat is de eventuele business impact van deze vertraging?
Op basis van deze informatie krijg je een zicht op de operationele kost en impact van de manuele afhandeling van deze beslissingen, en de potentiële return van een automatisatie. Indien er geen evidente business rules opgesteld kunnen worden om de beslissing automatisch te nemen, kan je vaak wel machine learning technieken inzetten om toch deels te automatiseren.
Dat gaat zo: elke genomen beslissing wordt samen met de beschikbare data rond de case samengebracht, en op een heel aantal van deze voorbeelden wordt een statistisch model gebouwd dat voor nieuwe, onbekende cases een voorspelling kan maken met de meest aanneembare voorspelling, samen met een zekerheidsfactor.
Dit soort machine learning modellen zijn tegenwoordig vrij eenvoudig te bouwen en te gebruiken: alle grote public cloud providers hebben SaaS oplossing die op basis van aangeleverde data een werkend machine learning model ter beschikking stelt, waardoor de investeringskost vaak verrassend laag is.
Uiteraard is dit geen exacte wetenschap, maar in praktijk is ook hier de 80/20-regel vaak van toepassing: een groot deel van de beslissingen blijkt zeer voorspelbaar op een beperkt set van informatie (features), en kan ingezet worden om een groot volume aan repetitieve beslissingen aan een geautomatiseerd systeem over te laten.
Als je de historische gegevens van beslissingen samen met alle procesvariabelen die voor de beslissing bekend waren in een machine learning model verwerkt kan je voor elke nieuw te maken beslissing het model inzetten om te kijken of er een automatische beslissing met een factor van zekerheid die hoog genoeg is, kan worden gemaakt.
Ingepast in een BPMN proces betekent dit dat de manuele beslissing optioneel wordt gemaakt, en enkel gevraagd wordt voor cases die niet met voldoende zekerheid beslist kunnen worden, of een sporadische steekproef die de accuraatheid van het machine learning model op lange termijn moet valideren.
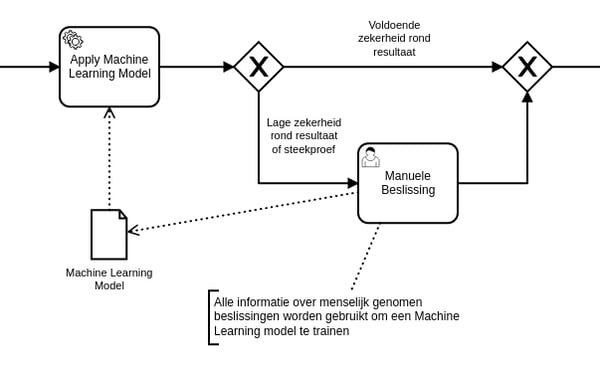
Welke mate van zekerheid nodig is om het proces op basis van automatische beslissingen verder te laten lopen, hangt uiteraard af van:
- De aard van de beslissing.
- Het risico.
- De impact van een eventuele foute beslissing.
Zelfs indien je de resulterende machine learning modellen niet inzet om automatisch beslissingen te nemen, kan je er nog steeds grote meerwaarde uit halen doordat je een zicht krijgt op de meest bepalende factoren die een beslissing beïnvloeden, of om manuele beslissingen die afwijken van de verwachting nog eens aan een andere gebruiker aan te bieden als counter validatie.
Voorbereiding op Robotic Process Automation (RPA)
In het stukje over integraties vanuit een BPM Engine bespraken we reeds de mogelijkheid om opzoekingen en manipulaties in externe systemen te automatiseren. In een aantal gevallen zijn deze integraties echter niet mogelijk, en zal een manuele taak nodig blijven om informatie op te zoeken of te registeren.
Door manuele taken expliciet in een procesmodel op te nemen, kan je minstens rapporteren hoe vaak die taak moet uitgevoerd worden, en hoeveel tijd ermee verloren gaat (zowel in uitvoer als in wachttijd tot iemand de taak oppikt). Dit biedt een uitgelezen mogelijkheid om enkele zaken te optimaliseren door de inzet van RPA (Robotic Process Automation).
Hierbij gaat een gespecialiseerd stuk software aan de slag met de taken, en via gesimuleerde gebruikersactiviteit op de aan te sluiten applicatie de nodige acties ondernemen. Net zoals een menselijke gebruiker taken opneemt uit de takenlijst die in de BPM Engine klaarstaat, doet de RPA Robot dat ook. Door de nodige repetitieve acties op te nemen of te scripten kan de RPA robot automatisch dingen opzoeken, spreadsheets updaten, externe databases of websites raadplegen, enz...
Als in uitzonderlijke gevallen (foutmeldingen in de applicatie, ...) de robot niet tot het gewenst resultaat kan komen wordt de taak typisch toegewezen aan een gebruiker, zodat er enkel tijd naar een beperkt aantal problematische cases gaat, en niet naar het gros van de succesvolle uitvoeringen.
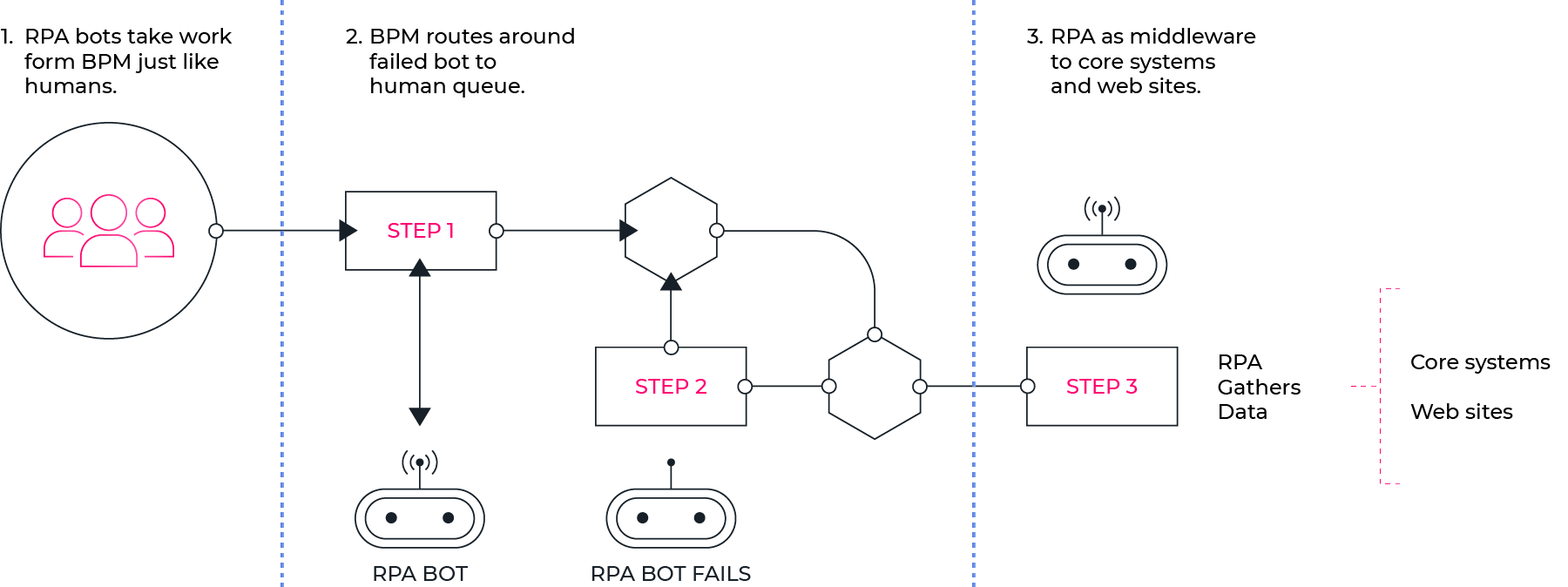
RPA is een techniek die vaak geen definitieve lange-termijn oplossing betekent, maar toch een zeer pragmatische oplossing kan zijn om reductie in kostbare mens-tijd én gemaakte fouten te bewerkstelligen.
Een BPM Engine integreren in software
Een BPM Engine kan je op heel wat verschillende manier positioneren in je architectuur. We zetten de belangrijkste mogelijkheden en afwegingen hier op een rijtje.
Centrale vs Decentrale BPM Engine
Een eerste belangrijke keuze die je zal moeten maken, is of je alle processen op één centrale BPM Engine zal beheren, dan wel een decentraal model hanteren en deeldomeinen van een aparte BPM Engine instantie voorzien.
Configureer je alle processen in één centrale BPM Engine, of voorzie je een aparte engine voor bijvoorbeeld alles rond het domein "sales", en een aparte rond het domein "customer service"?

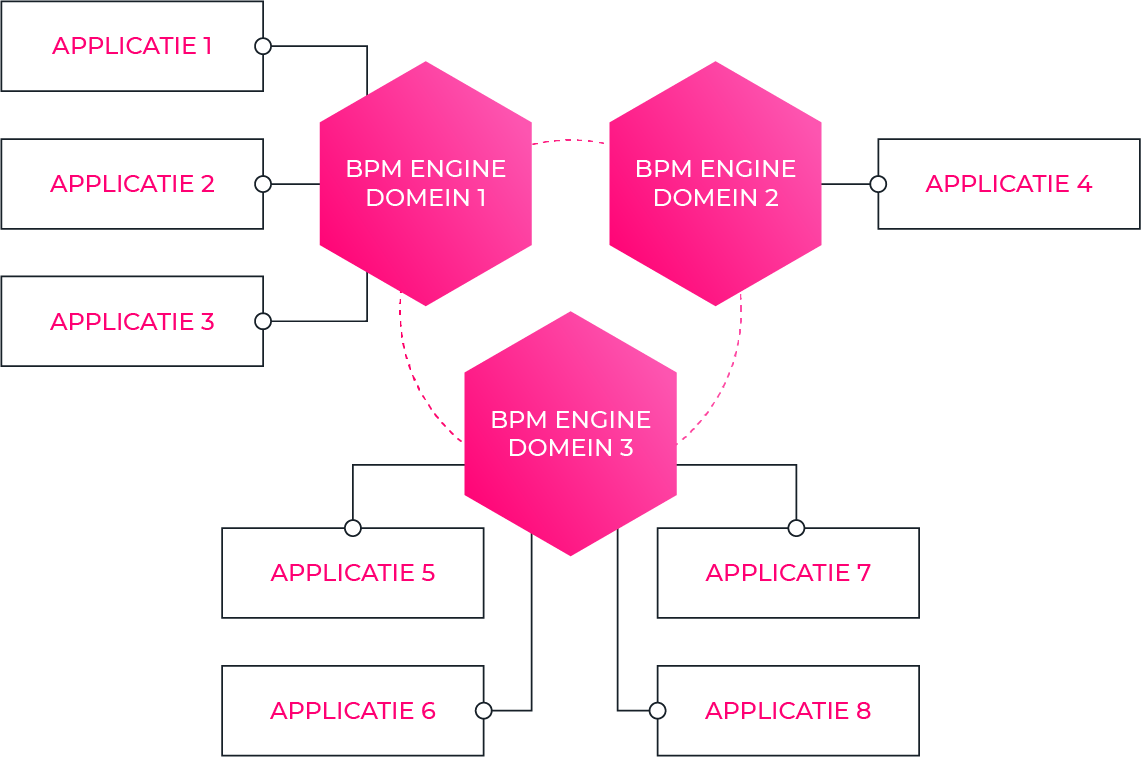
Afwegingen die je hierbij moet maken zijn uiteraard de onafhankelijkheid van de verschillende domeinen, alsook de mogelijkheid om die een eigen release kalender, levenscyclus en upgrade-planning te laten doorlopen - vaak is een decentrale aanpak hier aangewezen.
Als het licentiemodel het toelaat, heb je in grote projecten meestal baat bij het beheren van een specifieke BPM engine voor elk domein, waarbij de applicaties en processen die in dat domein vallen, samen beheerd en geversioneerd kunnen worden. Wijzigingen in dit domein hebben dan ook weinig of geen impact buiten dit domein. Dit voorkomt dat je teveel afhankelijkheid tussen de componenten gaat leggen en zo dreigt te eindigen met een gedistribueerde monoliet - een systeem dat verschillende componenten bevat, maar niet toelaat om ze effectief onafhankelijk van elkaar te onderhouden en te evolueren.
Rapportering is dan meestel weer evidenter in een centrale aanpak, alhoewel de meeste BPM Engine vendors wel oplossingen hebben om informatie van de verschillende processen vanuit de verschillende engines in één beeld te vatten.
Standalone vs embedded BPM Engine
Er zijn 2 manieren om een BPM Engine in relatie tot je applicatieve componenten te zetten: als een standalone BPM Engine of ingebouwd (embedded) in een software component.
Bij een standalone BPM Engine draai je de BPM Engine als een aparte server die als een extra component in je architectuur die voor de aansturing zorgt. Dit patroon is de klassieke aanpak die jaren geleden gangbaar was in de BPM wereld met de producten zoals die toen vorm kregen. Deze manier van werken centraliseert sterk, met alle daaraan verbonden nadelen en maakt de BPM Engine ook zeer visibel in de architectuur, vaak ontstaan er onbedoelde afhankelijkheden. Als je deze manier van werken hanteert, is het cruciaal om te zorgen dat je alle specifieke activiteiten en integraties buiten de BPM engine plaatst, om een complete monolitische oplossing te vermijden.
Een betere aanpak is meestal om de BPM Engine mee in je software-componenten te verwerken, te embedden. Deze aanpak is met de moderne BPM Engines zoals bv Flowable zeer evident, aangezien ze als een applicatieve library vormgegeven zijn, die vlot in een applicatie ingepast kan worden.
Hier kan je dan architecturaal nog eens twee types services gaan onderscheiden:
- proces services die primair de processen binnen een bepaald domein faciliteren maar op zich weinig of geen business data of gebruikers functionaliteiten bevatten,
- en domein services, die alle business data rond één specifiek domein beheren, maar typisch agnostisch zijn over de hoger liggende processen waar ze in betrokken zijn.
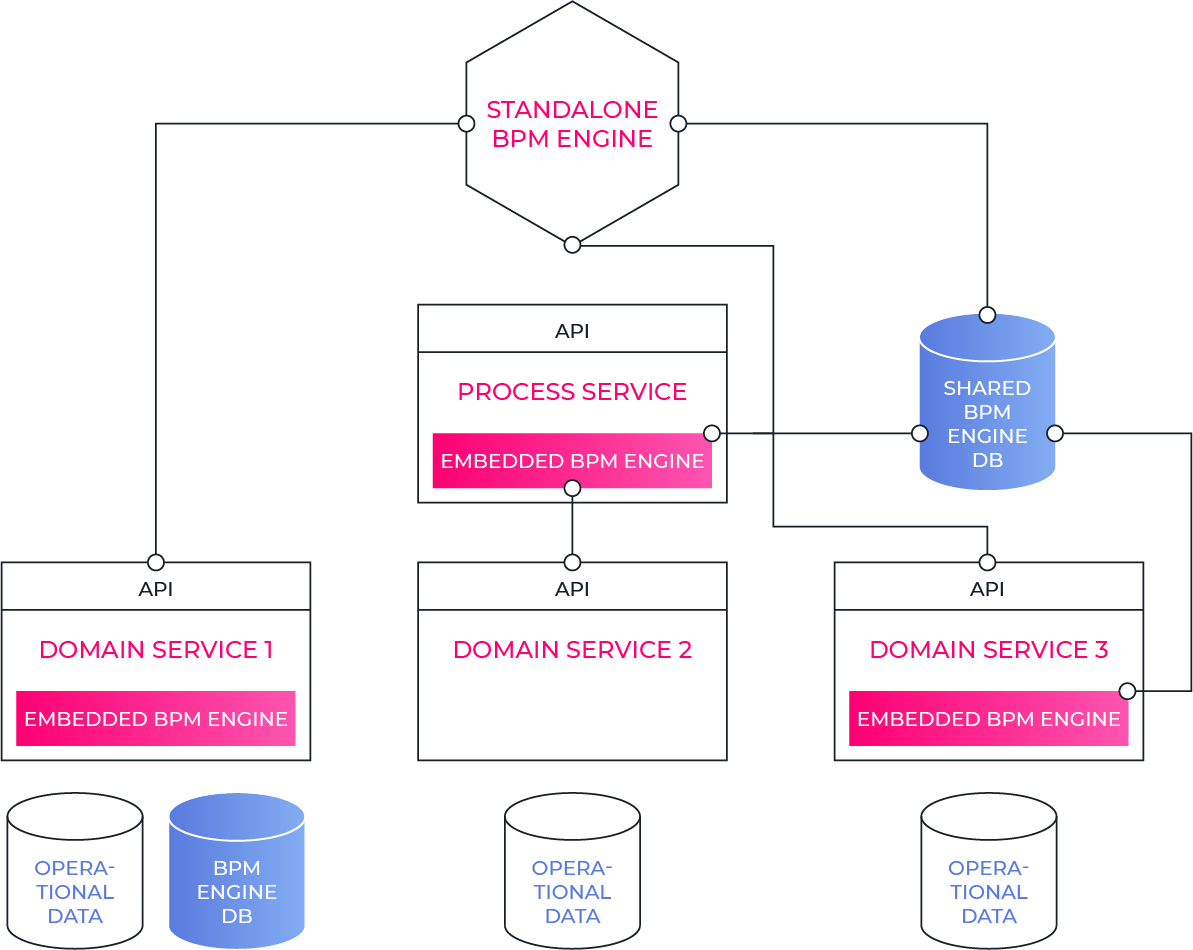
Als je een klassieke (micro)services architectuur hanteert mét een embedded BPM Engine voor die services waar het nuttig is, en die enkel ontsluit via de API van deze service, dan heb je letterlijk the best of both worlds, en de nodige onafhankelijkheid tussen de services bewaard.
Enig aandachtspunt dat dan overblijft, draait om je services niet te fijnmazig te maken en je processen zo versnipperd en onoverzichtelijk in te richten, al kan je dat ook weer oplossen door één proces service te bouwen die de interactie tussen enkele nauw verwante microservices binnen één domein orchestreert.
Deze combinatie vind je vaak: high-level processen in een aparte business proces component (proces services), gecombineerd met low-level processen in de specifieke services. Ook bestaat meestal de mogelijkheid om één gedeelde database te gebruiken zodat monitoring toch vanuit één centrale beheersapplicatie kan gebeuren, al moet je dan natuurlijk rekening houden met het feit dat al deze services eenzelfde versie van de engine moeten draaien en dus ook samen moeten geüpgrade worden, wat in een groot systeem met vele teams organisatorisch wellicht niet evident is.
Externe Worker services
Als je procesautomatisatie met een BPM Engine gaat doen, zal je heel veel activiteiten in je processen willen realiseren als een stukje code dat wordt uitgevoerd. Zeer eenvoudige dingen kan je gaan scripten en mee in het proces verwerken, maar goede software engineering vereist uiteraard dat je hiervoor een specifiek component gaat aanroepen dat extern draait aan de BPM Engine. In een service-oriented architectuur is het ook logisch dat die functionaliteit geboden wordt door de service die dit stukje domein representeert.
Deze "worker service" werkt op die manier taken af die het proces letterlijk weer een stapje verder helpen.
Er zijn hier ruwweg drie patronen in te onderscheiden:
- Je kan de worker service aanroepen via een API (REST of SOAP) - iets wat in de meeste BPM Engines standaard voorzien is of makkelijk te bouwen is.
Hierbij wordt er op het moment dat de activiteit (typisch een Service Task) moet uitgevoerd worden, een webservice call gemaakt naar een extern systeem dat de nodige acties onderneemt en een resultaat oplevert. (Geslaagde actie of foutmelding, met eventuele nieuwe informatie die als procesvariabelen beschikbaar worden in de rest van de uitvoering van het proces.) - Een BPM Engine voorziet meestal ook de mogelijkheid om een stukje code aan te roepen (bv Java klasse) - dit impliceert dan wel dat deze beschikbaar is in de BPM Engine zelf, wat niet altijd wenselijk is in functie van configuration management. Zeker als er meerdere procesversies ondersteund dienen te worden en hier ook meerdere versies van de service klasse nodig zijn, wordt dit vaak problematisch.
Je kan uit te voeren activiteiten klaar zetten op een Queue, en deze actief door worker services laten opvragen. Dit maakt het proces onherroepelijk asynchroon, maar biedt heel wat voordelen:
- Aangezien er een pull model in plaats van een push model gebruikt wordt, ontstaan er geen fouten als een worker service even niet actief is. De opdrachten stapelen dan gewoon even op op de queue, en worden terug weggewerkt als de worker service terug actief wordt.
- Ook naar schaalbaarheid toe is dit pull-model zeer handig: door het louter toevoegen van extra instanties van de worker service, kan een tijdelijk groter volume aan uit te voeren activiteiten vlot opgevangen worden.
Vooral de Camunda BPM Engine heeft hier mooie voorzieningen rond met het concept van External Tasks, maar in elke andere BPM Engine kan je dit patroon uiteraard ook zelf gaan inrichten. Best voorzie je dan wel monitoring en alerting op de queues, om te vermijden dat je processen onopgemerkt stilvallen bij een technisch probleem met een worker service, waardoor er geen taken meer afgewerkt geraken.
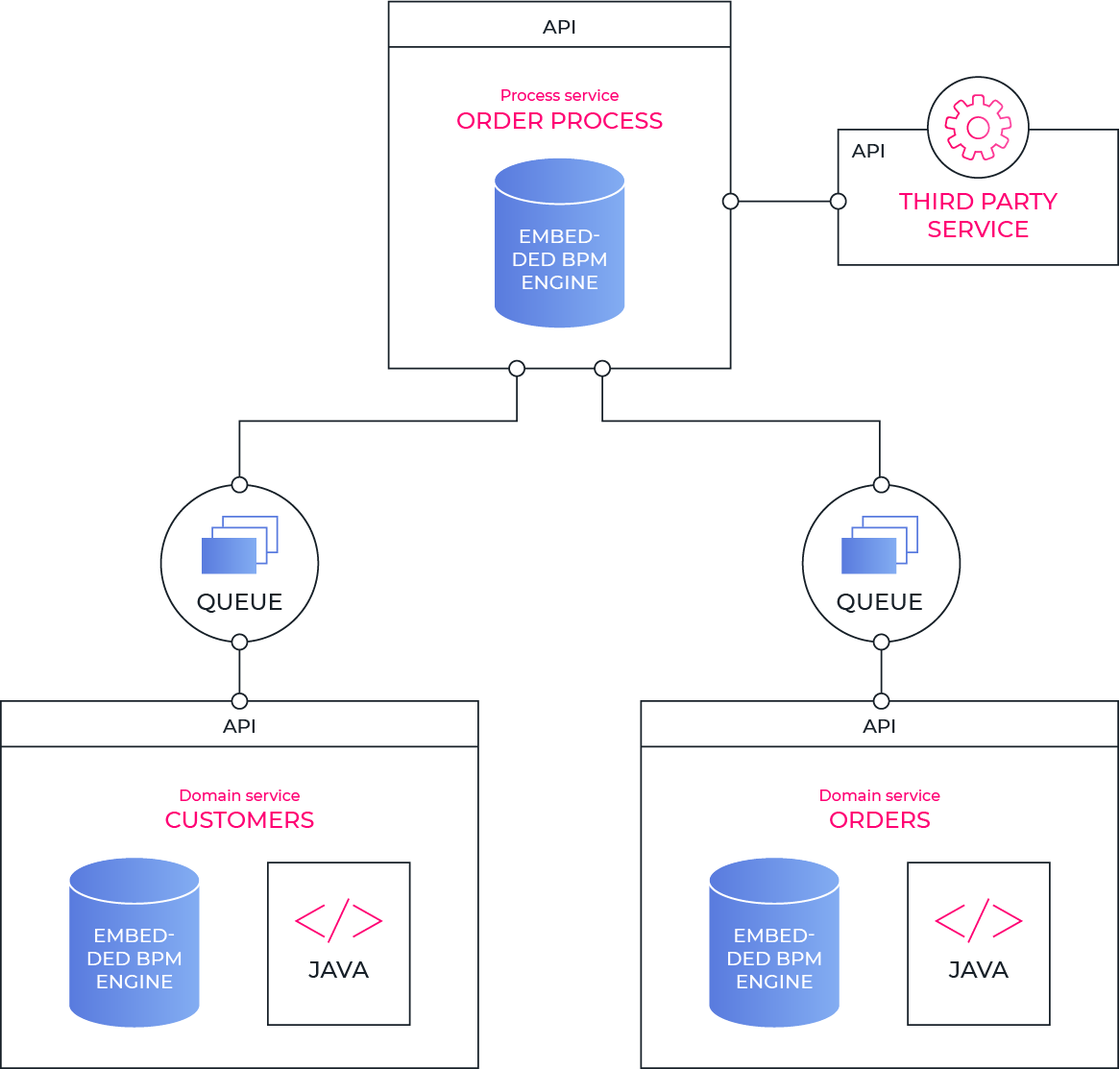
Teken voor jezelf altijd een aantal heldere architectuur- en design principes uit om deze keuzes bewust en niet ad-hoc te maken, bijvoorbeeld:
- "Een proces service met embedded BPM Engine integreert altijd met de aansluitende domein services via een queue".
- "Een domein service met embedded BPM Engine integreert door directe aanroep van een Java klasse die onderdeel vormt van de domein service zelf".
Microservice Orchestratie bij hoog volume
Als je je BPM Engine gaat inzetten als orchestrator binnen je microservices architectuur, bestaat de kans dat je uiteindelijk geconfronteerd wordt met een zeer hoog aantal processen, en nood aan een hoge schaalbaarheid. BPM Engines zijn meestal goed geoptimaliseerd om een degelijke performantie te leveren, maar het gebruik van een (al dan niet centrale) databank kan bijvoorbeeld wel effectief een bottleneck worden.
Helaas zijn hier geen standaard oplossingen voor, en zal je - mits een degelijk begrip van de werking van je BPM Engine - zelf de nodige architectuur aanpassingen moeten doen. Er zijn bijvoorbeeld mogelijkheden om een BPM Engine bovenop een NoSQL database als MongoDB te gaan draaien, of om deze te koppelen aan event stream processors zoals bijvoorbeeld Kafka.
Er ontstaat in deze niche ook een nieuwe reeks producten zoals zeebe.io, wat een aanpassing is van de Camunda BPM Engine die specifiek voorzien is om als microservice orchestrator ingezet te worden. Zeebe ondersteunt een beperkt aantal BPMN symbolen en vermijdt de centrale database bottleneck door lokale storage op alle nodes te gaan doen, wat maakt dat het makkelijk te schalen is aangezien het ontbreken van een centrale relationele database een belangrijke bottleneck vermijdt. Alle werk wordt in externe services gedwongen (sowieso al een best practice), en worden aangeroepen op basis van gRPC.
Process Driven Architecture
Een software architectuur uittekenen, laat toe om heel bewust om te gaan met de manier waarop je die structureert. De belangrijkste aspecten hierin zijn hoe je je systeem in verschillende componenten opdeelt, en welke interactie deze componenten met elkaar mogen of kunnen hebben.
Vanuit deze opdeling kunnen dan ook heel wat andere aspecten afgesproken en ingeregeld worden,
- van het ownership (wie werkt aan welk component en wie neemt er finaal beslissingen rond)
- over release management (welke versies houden we aan en op basis van welke criteria mogen die uitgerold worden)
- tot monitoring (welke componenten draaien goed, welke hebben een probleem en wat is daar dan de impact van?).
Vaak kom je nog een opdeling per applicatie tegen - puur op basis van functionaliteiten die in functie van een bepaalde business nood samengebundeld werden, waarbij de deliverable van het project tot een applicatie leidde. Dit geeft aanleiding tot ownership op applicatieniveau maakt hergebruik moeilijker, veroorzaakt duplicatie van logica en data over applicaties heen, enz...
Een service-georiënteerde aanpak gaat anders te werk: hier worden een aantal zo onafhankelijk en zo herbruikbaar mogelijke services bepaald, en worden er gebruikersapplicaties en integraties daar bovenop gemaakt. Deze services zijn in principe vlotter herbruikbaar en individueel evolueerbaar.
De vraag is dan natuurlijk op welke basis je deze services gaat bepalen. In praktijk zie je vaak een aanpak die data-gebaseerd tewerk gaat. Hoewel het logisch lijkt vanuit IT-technische insteek om een component per stukje informatie-model op te stellen en daar de nodige functionaliteiten bovenop te bouwen, biedt dit in praktijk weinig handvaten voor een vlot beheer. Het ownership van een "klanten" service is namelijk moeilijk bij één business unit of functie neer te leggen, enz ...
In dit hoofdstuk verkennen we enkele voordelen van software ontwikkeling met business processen als ankerpunt in de architectuur, iets wat met BPM Engines uiteraard zeer vlot te realiseren is.
Voordeel 1: Processen als uitgangspunt
Een goede aanpak is om de architectuur van je software in lijn te brengen met de business processen die je uittekent. Voor elk business proces maak je dan een software component - bijvoorbeeld "facturatie" aan, eventueel aangevuld met een lager liggende component "factuur" die zich beperkt tot een redelijk eenvoudige data storage en bevragingsmogelijkheden biedt. Elke service die een proces representeert zal de nodige functies ter beschikking stellen via een API Contract om ermee te interageren - net zoals in een klassieke service-georiënteerde benadering, maar in plaats van vaak beperkte data storage functionaliteit zal een veel rijker proces-model ontsloten worden, waar processen geïnitieerd en bevraagd kunnen worden, en de nodige triggers worden gegeven om een lopend proces verder te laten lopen.
Door deze aanpak geef je de opdeling ook vanuit business perspectief een bestaansreden, en zal je zien dat ownership veel duidelijker is (de proces owner wordt uiteindelijk eenvoudigweg ook de service owner), en dat wijzigingen in business processen ook veel kleinschaliger in de architectuur zullen blijven. Beiden zijn belangrijke aspecten in een alignering van business en IT.
Voordeel 2: Duidelijk ownership
Als er één ding duidelijk is bij een proces-gedreven aanpak, is dat elke architectuur component dan één duidelijk aanwijsbare business owner heeft: de proces owner. Het feit dat elk proces zich één-op-één vertaalt in een component in de architectuur, geeft een zeer transparante opbouw en een duidelijke link naar de business-organisatie. Dit is vaak helemaal niet rechtlijnig in een architectuur waar een data-gebaseerd model of zelfs domain driven design wordt toegepast (een bounded context wordt te vaak arbitrair toegewezen).
Dit betekent dat het veel eenvoudiger wordt om de juiste stakeholders te betrekken bij het ontwerp en de realisatie van het component, en vermijdt dat er te brede consensus gevonden moet worden over vereisten, prioriteiten en de release kalender van een component, wat veel efficiënter werkt.
Voordeel 3: Processen als basis voor scoping
Scoping van een software project is een belangrijke maar moeilijke opdracht. Hoe creëer je een juist beeld van wat wel en niet gepland wordt, naar stakeholders met een diverse achtergrond van puur business tot zeer IT-technisch toe? De scope van je project vormt de basis voor elke planning en budgettering, dus misverstanden rond scope hebben per definitie altijd een impact op deze factoren.
Deze problematiek wordt vaak ook aangepakt door een agile project aanpak, waarbij de exacte scope (of de invulling daarvan) niet exhaustief vooraf gebeurt, maar er gaandeweg in groep naar een eindpunt wordt toegewerkt, startend met de meest fundamentele zaken, zodat telkens een herevaluatie van resterende scope, budget en tijd kan gebeuren op basis van nieuwe inzichten en een up-to-date status.
Een techniek die te weinig wordt toegepast is om te gaan scopen op basis van business processen. Deze kunnen in ruwe vorm vrij snel vorm krijgen, en voor alle stakeholders begrijpelijk zijn en hetzelfde beeld creëren. Door eenvoudigweg de processen te benoemen én te modelleren creëer je al een duidelijk valideerbaar scope-overzicht dat zich één-op-één vertaalt naar een architectuur.
Deze krijtlijnen even helder uittekenen op basis van analyses, user stories, schermschetsen, domein modellering e.d. is vaak moeilijk, vergt een grotere investering in tijd en middelen en is vaak een aanleiding tot misverstanden en discussies. Waar mogelijk, vormen deze technieken wel een zeer goede aanvulling op een proces-gedreven aanpak.
De elementen van een business proces geven alvast een stevige houvast:
- Pools & swimlanes: welke organisaties, rollen, actoren zijn betrokken?
- Activiteiten: welke zien we in scope of out of scope voor de software?
- Business rules en beslissingen: welke zijn er te nemen, hoe complex zijn die?
Belangrijk is dat een procesmodel deze ook volledig op elkaar laat inhaken, waar een klassiekere analyse vaak een meer versnipperd beeld geeft.
Naast de scope-aflijning geeft een proces-gedreven aanpak ook een goede houvast naar de bepaling van de diepgang van de scope: welke activiteiten worden manueel uitgevoerd, beperkt door software ondersteund of net heel compleet uitgewerkt?
Op deze manier kan je heel bewust prioriteiten gaan stellen en stapsgewijs uitdiepen zonder het end-to-end verhaal uit het oog te verliezen.
Als je bijvoorbeeld een ID-check van een nieuwe klant moet doen dan zal dit uiteraard als een activiteit in je proces opgenomen zijn. Of dit een manuele taak is die offline verwacht wordt te gebeuren, of je een interface voorziet waar je op basis van een beeld "Aanvaard" of "Weiger" kan klikken, dan wel een volledige integratie met een geautomatiseerd system is, wordt dan een keuze in functie van de business waarde en operationele noodzaak (volume aan aanvragen, risico, enz...). Door deze aanpak zal je uitsluitend investeren in features waarvoor een duidelijk aantoonbare business case is.
Voordeel 4: Visueel en transparant
Meer dan eender welke andere techniek laat BPMN toe om visueel samen te werken met mensen met een zeer diverse achtergrond en functie. Business Processen kunnen als een visuele tool in het team gehanteerd worden en gesprekken en discussies faciliteren. Ze laten toe om tot zeer diep in het ontwikkelproces iedereen aangesloten te houden.
Ook naar testing toe, scheppen procesmodellen duidelijkheid over de de volledige scope én alle mogelijke paden door het systeem, en kunnen ze de basis zijn voor test design. Daarnaast laten ze toe om in een vroege fase de volledige werking van het systeem te visualiseren zonder visuele schermen of detail-logica, maar met business regels, beslissingen en de "flow" tussen mensen en het systeem als basis, om snel te kunnen valideren of we het juiste aan het bouwen zijn.
Voordeel 5: Betekenisvolle informatie voor business
Tenslotte zijn er ook at runtime heel wat voordelen aan een proces-gedreven architectuur, niet in het minst de nuttige informatie naar business toe die zo'n applicatie genereert. Omdat de hele software vormgegeven is rond de uitgetekende business processen, worden hier rond ook vlot de nodige metrics opgebouwd.
Heel wat business vragen kunnen dan ook één-op-één beantwoord worden door analyse van de proceslogging, wat anders mogelijks complexe data-extractie, BI technieken en rapportering zou vergen:
- hoeveel lopende processen zijn er, en wat is de evolutie hierin?
- hoeveel uitzonderlijke cases zijn hier bij en hoeveel tijd steken we daar manueel in?
- welke fouten komen er voor en hoe vaak doen die zich voor?
- waar treedt er vertraging op en waar is er ruimte voor verbetering, e.d.?
Best practices voor BPM Projecten
Als je Een BPM Engine zoals Flowable of Camunda in je software-ontwikkeling gaat opnemen, brengt dit uiteraard ook enkele nieuwe uitdagingen met zich mee, we lijsten hier de belangrijkste aandachtspunten op om even bij stil te staan.
Best practices op het gebied van team & organisatie
Om de meerwaarde van procesmodellering te halen, is een samenwerking met business en SME's (Subject Matter Experts) belangrijk. Bekijk een procestool niet louter als een technisch component dat implementatie makkelijker kan maken, hoewel dat uiteraard wel een deel van het verhaal is. De transparantie die procesmodellering geeft als je deze in de software inbouwt, is net bedoeld om business nauw betrokken te krijgen in de hele effort. In praktijk betekent dit dat deze mensen meer dan ooit binnen een ontwikkelteam kunnen opgenomen worden en de deliverables mee kunnen vormgeven, in plaats van enkel input voor te bereiden en het ontwikkelproces dan z'n gang te laten gaan tot er kan getest worden.
Best breng je bij aanvang van het project en bij onboarding van nieuwe mensen de basiskennis rond BPMN en business processen in het algemeen op peil. Dit hoeft vanwege de intuïtieve symboliek geen grote oefening te zijn, maar een goed begrip van concepten als een pool, activiteit, gateway, message event e.d. is zeker nuttig. Vaak kan een workshop met opfrissing van de basisconcepten en een uitgewerkt referentie-voorbeeld de nodige basiskennis, en daarmee ook het nodige vertrouwen geven om aan de slag te gaan. Bedoeling is dat het hele team van ontwikkelaars, over de product owner tot SME's en alle stakeholders, de procesmodellering effectief als een rijke gemeenschappelijke taal gaan ervaren om vlot samen te kunnen werken.
Dat brengt ons bij een laatste belangrijk aspect: laat zeker niet na om zeer visueel te werken: hou procesmodellen niet verstopt in een digitale modelleringstool, maar hang deze in groot formaat in je projectruimte. De conversaties, afstemmingen en discussies die hierdoor gefaciliteerd worden, zullen je projectinzicht naar een hoger niveau trekken.
Best practices bij het modelleren van processen
Het modelleren van processen gebeurt uiteraard best in een tool die toelaat om samen te werken op deze modellen, ze te versioneren, e.d. Belangrijk is dat deze als een gedeelde deliverable tussen business en IT gezien wordt. Als je ambitie hebt om de procesmodellen uitvoerbaar te maken in een BPM Engine, zullen ze sowieso verder moeten uitgewerkt worden tot dit IT-technisch mogelijk is (BPMN modellering op level 3 - executable), maar ook business moet deze als "haar" processen beschouwen om te vermijden dat ze afzwakken tot een visuele codeer-tool voor de ontwikkelaars.
Om dit alles gestructureerd aan te pakken wordt er best ook werk gemaakt van een procesarchitectuur, een manier waarop aan proces identificatie wordt gedaan, en een stukje standaardisatie.
- De procesarchitectuur moet een high-level overzicht zijn van alle processen die relevant zijn naar het project toe. Deze kunnen perfect zeer high-level starten (marketing, sales, enz...) en hiërarchisch afdalen naar de meer specifieke processen, waardoor ze als het ware een wereldkaart vormen waarrond het hele projectteam zich kan gaan organiseren.
- De manier waarop je aan proces identificatie doet is hier nauw mee verbonden: welke activiteiten groepeer je samen in een proces? Maak je één groot proces, of net enkele kleinere? Wat zijn de mogelijke start events en eind events van elk proces, en vaak minder makkelijk dan het lijkt: wat is de juiste naam voor elk proces.
- Daarnaast is het ook belangrijk dat je naar enige vorm van standaardisatie toewerkt: een soort stijlgids bij het modelleren van processen, naamgeving van activiteiten en processen, enz...
Ga je bijvoorbeeld voor procesnamen die "Order Process" of eerder een naamgeving die start en einde beter weergeeft zoals "Quote-to-Order"? Breng je wat structuur in het aantal "lagen" in het procesmodel tussen de high-level processen, de gedetailleerde business processen zelf, en de eerder "technische" processen die integraties met andere systemen realiseren, en vaak toch een IT-technisch karakter krijgen?
Enkele praktische tips die je bij procesmodellering best hanteert zijn:
- Vermijd een mix van business en technische activiteiten in één procesmodel. Hou een procesmodel ofwel volledig op business proces niveau, begrijpelijk voor niet-technische gebruikers en ontdaan van technische stappen integraties, ofwel volledig op technisch niveau, met deelfunctionaliteit dit perfect abstraheerbaar is naar business toe. Splits, waar nodig, subprocesssen met technische stappen af om dit te realiseren.
- Modeleer processen niet als een losstaand gegeven, maar link procesmodellen zeer duidelijk met de andere modellen en analyses die je maakt: zorg dat alle organisaties, departementen en rollen die als pool of swimlane voorkomen duidelijk beschreven zijn in een organisatie-model. Zorg ook dat elke business entiteit (dossier, order, product, levering, ...) eenduidig gespecifieerd is en een plaats heeft in je informatie-model link met andere - informatiemodel, organisatiemodel (rollen & organisaties). Alternatieve namen of verwarrende naamgeving vergroot de kans of misverstanden en bemoeilijk net de communicatie. Overweeg eventueel een standaard als SBVR (Semantics of Business Vocabulary and Rules) als referentiepunt hiervoor.
- Scheid processen en business rules duidelijk, en zorg dat processen niet geïmpacteerd raken als regels wijzigen. Gebruik eerder DMN tabellen dan gateways om beslissingen over routering te nemen op basis van data.
Best practices bij het implementeren van processen
Of je nu een Process Driven Architecture aanhoudt, of een klassiekere aanpak verkiest, bij het in software integreren van een business process hanteer je best een goede mix van factoren zoals de volgende:
- Gebruik een aparte proces component in de architectuur die orchestratie doet over de andere services heen. Hou dit proces volledig ontkoppeld van de achterliggende diensten om een gedistribueerde monoliet te vermijden.
- Embed de BPM Engine in applicatieve componenten die groot genoeg zijn om deze te rechtvaardigen (meer dan triviale processen).
- Ontsluit elke applicatieve component via een API, gebruik die ook om processen te initiëren, hun status te bevragen, messages te sturen, e.d. Vermijd zo een directe afhankelijkheid van andere componenten in je architectuur op de BPM Engine en diens API, en hou een vlot update-, upgrade- en vervangingspad voor de BPM Engine open.
- Prefereer asynchrone over synchrone werking - in functie van schaalbaarheid, performantie en minder risico op falen. Zorg ook dat er geen onnodige vertraging in de feedback naar gebruikers optreedt door een al te groot deel van een langlopend proces synchroon uit te voeren. Enkel als het volledige proces in één beweging tot resultaat voor de gebruiker of het aanroepende proces zal leiden (short-lived) is het nuttig om dit synchroon te laten verlopen.
- Gebruik enkel procesvariabelen die echt nodig zijn om het proces te faciliteren en om routering te kunnen doen. Hou de master rond alle business data bij in applicatieve services en nooit alleen in de procesvariabelen. Dit bevordert de beheersbaarheid van de applicatie indien er ingegrepen moet worden, en maakt rapportering op deze informatie mogelijk zonder de processen te bevragen.
Best practices rond het testen van processen
Aangezien alle input en output van een proces mooi uitgemodelleerd wordt, is een automatisatie van alle mogelijke testscenario's die exhaustief alle paden door het proces aanraken meestal vlot mogelijk. Vaak is dit dan ook de beste manier om end-to-end testing van processen aan te pakken. Bedenk wel dat je best de aparte activiteiten die aangeroepen worden als een aparte eenheid test, anders wordt de root cause analyse van een test failure meestal problematisch.
Enkele specifieke aandachtspunten zijn hierbij aan te stippen:
- Langlopende processen en processen met asynchrone acties zijn vaak moeilijk end-to-end geautomatiseerd te testen. Denk aan user input, tijdsgebaseerde acties die moeilijk na te bootsen zijn in een testscenario, enz... Of je moet hier een investering doen om de nodige tools en practices te voorzien om dit degelijk in te richten, of je moet de verschillende componenten mocken en zo het proces als geïsoleerd item gaan testen.
- Ga uit van zowel een whitebox- als een blackbox-testing approach. Bij de eerste aanpak bekijk je het proces en verken je alle paden, beslissingen en stappen die er bij komen kijken om de nodige testscenario's en testdata te bepalen. In de tweede fase maak je abstractie van de werking en beschouw je enkel de mogelijke input en verwachte output om dit te doen.
- Stel een sanity-suite van testen op die de correcte werking van de belangrijkste end-to-end processen in de software snel kunnen valideren - liefst na elke development-aanpassing (git push, ...)
Best practices rond de monitoring van processen
Een degelijke aanpak rond het monitoren van proces-gedreven software is belangrijk, maar vereist een licht andere aanpak dan bij klassieke software. Er zijn veel situaties te bedenken waarbij alle componenten technisch gezien vlot draaien maar er toch geen succesvolle end-to-end processen doorlopen worden. Denk aan oneindige loops in een proces, procesfouten die als probleem worden aangevlagd en functioneel leiden tot een opstapeling van manueel te behandelen processen, enz...
Belangrijk is dat je een aantal metrics in een monitoring dashboard opneemt om een correcte werking van het systeem vast te stellen, zoals het aantal processen die vastgelopen zijn op een fout, en het aantal lopende processen in het algemeen. Daarnaast is het vaak nuttig om de informatie die een BPM Engine verzamelt te ontsluiten in een operationeel dashboard, zoals de doorlooptijden per proces type, en de wachtlijst en wachttijden voor manuele taken.
Best practices rond de versionering van processen
Een beslissing die je ook moet nemen is hoe je omgaat met versionering van processen, en of je deze mee in je release management met de software laat lopen, dan wel als data of configuratie beschouwt die je apart in een omgeving kan laden.
De beste oplossing is vaak om de processen vanuit de modelleringstool in een BPMN-file te bewaren en deze samen met de applicatiecode te versioneren in je SCM (Source Control Management) tool zoals git, aangezien er typisch een sterke afhankelijkheid tussen de code en de procesmodellen is. Dit zorgt dat de versie van code én processen samen degelijk getest wordt door de ontwikkelstraat, en wordt er vermeden dat er processen en applicatie-code voor de eerste keer in deze unieke combinatie samenkomen in productie. Alle opties rond het integreren van procesmodellen in je CI/CD pipeline hebben we samengevat in een blog post.
Al snel zal je ook op het meest delicate punt in een software ontwikkeling met een BPM Engine stoten: het migreren van processen naar een nieuwere versie. Typisch zal een BPM tool bij elke wijziging aan een proces een nieuwe versie aanhouden. Lopende processen worden dan nog afgehandeld in de oude definitie, en nieuwe processen starten standaard in de nieuwe definitie. Of dit de gewenste gedraging is zal afhangen van de situatie - bijvoorbeeld of de wijziging aan het proces louter een optimalisatie is, of gebeurt om een probleem met de huidige versie op te lossen.
Uiteraard is het mogelijk om deze verschillende versies naast elkaar te laten bestaan, maar al snel zullen de nadelen hiervan zichtbaar worden:
- Alle rapportering in de BPM-engine zal typisch per procesversie gaan werken, wat een weinig helder beeld op het geheel geeft en op zich al een reden is om een procesmigratie naar de recentste versie te ondernemen.
- Ook het herhaald testen van alle nog actieve procesversies die in productie zijn, wordt al snel een huzarenstukje - zeker als je heel wat langlopende processen hebt, dreig je een te groot aantal procesversies te gaan moeten ondersteunen.
Het migreren van procesversies kan echter heel wat onvoorziene problemen veroorzaken: de status van een oud proces kan een onlogische of onmogelijke status opleveren in het nieuwe proces, sommige procesvariabelen waren niet voorzien in de oude versie en dreigen uitvoering in het nieuwe model in gedrang te brengen, en als het proces stevig hertekend is, is een migratie soms helemaal uit te sluiten.
Enkele belangrijkste tips om hier slim mee om te gaan:
- Hou procesmigratie ten alle tijd in het achterhoofd - vraag je altijd af hoe je bepaalde proceswijzigingen gaat uitrollen en wat de eventuele impact op lopende processen kan zijn.
- Vermijd dat je processen te vaak moeten aanpassen - plaats bijvoorbeeld beslissingen rond routering en business rules in een DMN tabel in plaats van op gateways, wat het proces onaangeroerd laat bij wijzigende business rules.
- Ondersteun een zo beperkt mogelijk aantal procesversies, liefst maximum twee versies per procesdefinitie, zo beperk je de werklast naar volgende versies toe.
- Hou geautomatiseerde testen aan voor alle aparte procesversies die je nog wil ondersteunen. Zo vermijd je onvoorziene problemen bij procesaanpassingen.
- Test procesmigraties uitvoerig voor het releasen van de nieuwe versie - eens gemigreerd is er vaak geen weg terug. Werk zowel gemigreerde als nieuw geïnitieerde processen verder af ter validatie.
- Verken en gebruik de ondersteuning voor procesmigraties van de diverse tools. Hoe sneller je afscheid kan nemen van historische procesversies, hoe vlotter je je systeem kan blijven evolueren.
Meer leren over BPM en BPM Engines?
Business Process Management is een uitgebreid onderwerp. Hieronder geven we alvast enkele nuttige aanknopingspunten om je verder in te werken.
BPM Engines
Een goed startpunt zijn alvast de verschillende vendoren van moderne BPM Engines. We geven hier enkele voorbeelden mee van Java-gebaseerde open source tools die ook een commerciële versie hebben:

Flowable BPM: www.flowable.org (open source) en www.flowable.com (commercieel) |

Camunda BPM: www.camunda.com met zeebe.io als specifieke oplossing voor microservices orchestratie |
Standaarden
De meeste BPM Engines ondersteunen volgende drie standaarden van OMG (The Object Management Group), waarrond je online veel goede tutorials vindt:
- BPMN - https://www.omg.org/bpmn/
- CMMN - https://www.omg.org/cmmn/
- DMN - https://www.omg.org/dmn/
Certificaties
OMG biedt een BPM certificatie-traject aan: OCEB2 (OMG Certified Expert in Business Process Management). Deze certifcatie focust op BPMN kennis, maar gaat ook zeer breed naar Business Rules, Methodologie, enz...
Deze certifcatie focust op BPMN kennis, maar gaat ook zeer breed naar Business Rules, Methodologie, enz...
Ze bestaat uit een Fundamental level, waarna het programma opsplitst in een Business en Technical track, elk met een Intermediate en Expert level. Het niveau van dit certificatie-examen overstijgt sterk algemene basiskennis en is zeker een meerwaarde om naartoe te werken als je deze onderwerpen grondig wil verkennen.
Boeken
Rond het onderwerp van Business Process Management zijn volgende boeken zeker het lezen waard:
 |
 |
 |
| 978-3662565087 FUNDAMENTALS OF BUSINESS PROCESS MANAGEMENT (2nd Edition) |
978-1541163447 |
978-0128003879 BUSINESS PROCESS CHANGE (THE MK/OMG PRESS) |
|
Geeft een goed overzicht van BPM in de breedte, met onder andere ook een aantal technieken om gestructureerd met business proces identificatie om te gaan. |
Van de hand van de ontwikkelaars van Camunda BPM. Dit boek geeft een platform-agnostisch praktisch inzicht in de toepassing van BPMN, en raakt ook CMMN en DMN aan. |
Iets theoretischer en zwaarder, met de focus meer op de organisatorische en strategische kant van BPM. |
 |
 |
|
|
978-0941049146 |
978-0128053522 |
|
| Een boek met de focus volledig op business rules en hoe deze op te stellen. | Geeft een overzicht van alle onderwerpen die je moet verkennen om je OCEB2 Fundamental certificatie voor te bereiden. Alhoewel een goed startpunt, is het louter voorbereiden op het certificatie-examen basis van dit boek te beperkt. |
